
The AI race is heating up like never before. As of May 2025, OpenAI, Anthropic, Google, and xAI have all dropped their newest flagship models—ChatGPT (GPT-4.5/4.1), Claude 4 (Claude 3.7 Sonnet), Gemini 2.5 Proa Grok 3. Each one promises major leaps in intelligence, creativity, reasoning, and tool use—and this time, the hype isn’t just marketing. These models are genuinely more useful, more capable, and in many cases, shockingly good.
But the question remains: which one is actually best? The answer depends on what you’re looking for. Some excel at coding or technical tasks, others are better at conversation, real-time knowledge, or working with huge documents. What’s clear is that we’re finally at a point where AI isn’t just a novelty—it’s something people can lean on every day for real work, research, or creative help.
All reviewed models (such as ChatGPT, Claude, Gemini, Grok, Perplexity a DeepSeek) are now available in Fello AI. All in one place. Stáhnout!!
In this guide, we’ll compare the top models head-to-head across all the key areas: general knowledge, math, programming, creative writing, tool use, and more. Whether you’re a developer, writer, analyst, or just someone curious about AI, this breakdown will help you understand what each model does best—and where each one still has room to grow.
General Knowledge & Conversation
One of the most important tasks for any AI model is answering questions accurately and holding a natural, helpful conversation. Whether it’s explaining history, breaking down science concepts, or just chatting fluently, this is where most users first test a model’s intelligence.
We compared the top models using the MMLU benchmark (which tests knowledge across 57 subjects) and real-world conversational experience. While all three contenders perform at a high level, subtle differences in tone, reasoning, and personality shape the user experience.
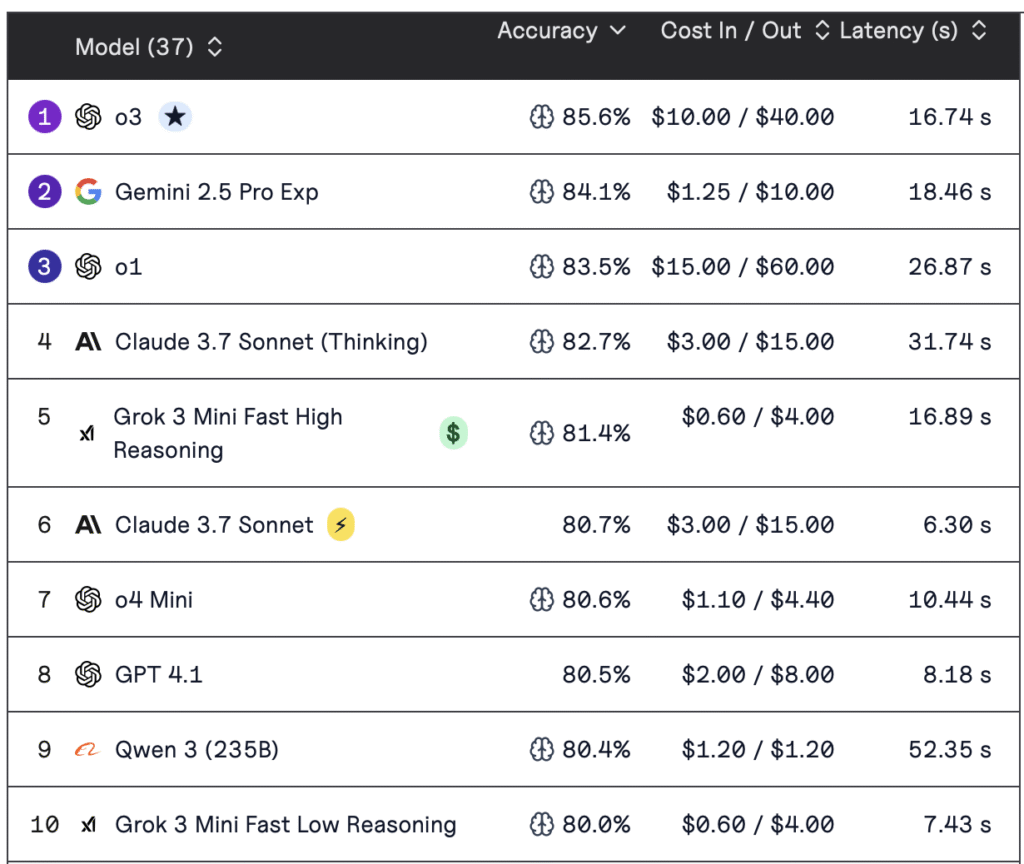
Winner: ChatGPT (GPT-4.5 / o3)
ChatGPT holds a narrow lead in general knowledge and natural conversation. Its latest model, GPT-4.5 (often referred to as GPT-4.1 or part of the “o-series”), scored ~90.2% on MMLU, outperforming both Claude 4 a Gemini 2.5 Pro, which sit in the 85–86% range. That translates into more accurate, confident answers across domains like history, law, science, and social studies.
What sets GPT-4.5 apart is not just recall but conversation quality: it’s fluent, emotionally aware, and adapts its tone well. Sam Altman described it as the first model that “feels like talking to a thoughtful person.” Combined with its strong multilingual performance and formatting control, it makes for the most polished general-purpose assistant available today.
Runner-Up: Gemini 2.5 Pro
Gemini matches GPT-4.5 closely in coherence and logic. It scored ~85.8% on MMLU, but it often shines in reasoning-heavy or scientific prompts thanks to native chain-of-thought processing. It’s especially strong when users ask complex, multi-part questions—handling them with structured, logical replies. While its tone is a bit more neutral, Gemini feels like a highly capable research assistant baked into Google’s ecosystem.
Claude 4 (Claude 3.7 Sonnet)
Claude delivers friendly, detailed responses with excellent contextual memory. Its 85–86% MMLU score puts it on par with Gemini, but it stands out with a massive 200K token context window, ideal for document analysis. Its hybrid “Extended Thinking” mode allows it to think deeper on complex queries. While slightly behind in precision, it’s often preferred for its warm tone and helpfulness in longer conversations.
Coding & Software Development
As large language models become more integrated into developer workflows, their ability to write, edit, and understand code is a major differentiator. Whether it’s generating new functions, debugging existing code, or explaining complex logic, the top AI models in 2025 are competing to become your go-to programming assistant.
This section compares Claude 4, Gemini 2.5 Pro, and GPT-4.5 in real-world coding scenarios, using benchmarks like SWE-Bench (for code generation) and Aider (for code editing). We’ll break down which model performs best, how they handle reasoning, and where each one shines in everyday dev work.
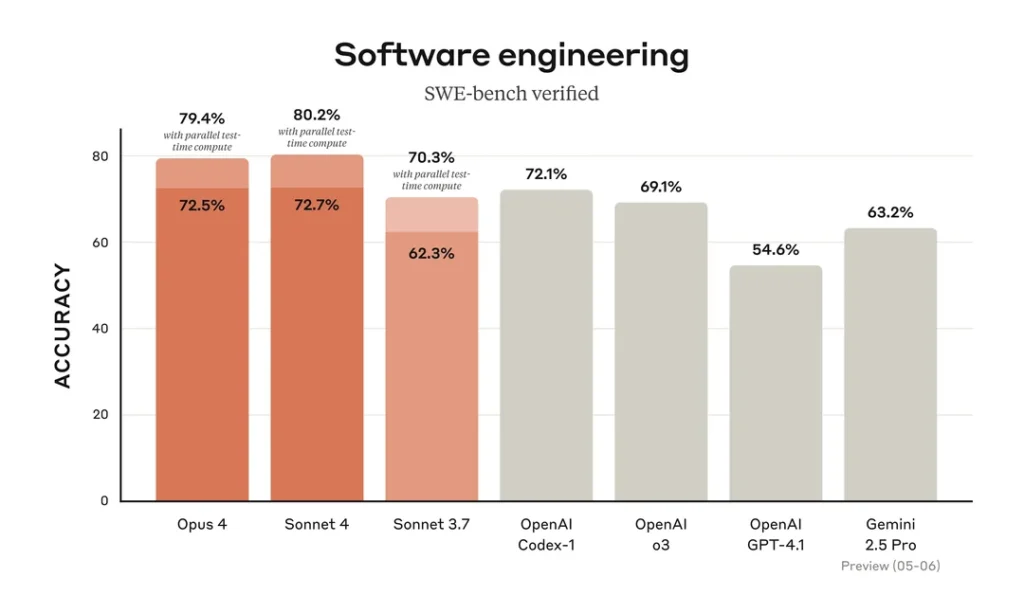
Winner: Claude 4 (Claude 3.7 Sonnet)
Claude currently leads in code generation accuracy, hitting 62–70% on SWE-Bench, a benchmark simulating real-world programming tasks. Its strength lies in extended reasoning mode, which allows it to “think through” problems deeply, explain its logic step by step, and even act as a lightweight agent in coding environments. Developers have praised its ability to debug, refactor, and plan code across large projects—especially when working within tools like Claude Code IDE integrations.
Runner-Up: Gemini 2.5 Pro
Gemini excels at code editing, scoring 73% on the Aider benchmark. It’s also impressive in end-to-end coding workflows, particularly when multimodal inputs (like design mockups or annotated images) are involved. Gemini’s structured, reasoning-heavy approach makes it a powerful coding companion—especially for developers already in Google’s ecosystem.
Also Solid: GPT-4.5 (ChatGPT)
GPT-4.5 achieves ~54.6% on SWE-Bench. While slightly behind Claude and Gemini on raw code generation, it remains highly reliable for instruction-following and generating clean, well-formatted code, especially with precise prompts. It’s widely integrated across IDEs and developer tools, making it a practical choice for general software development.
Math & Complex Reasoning
Solving math problems and multi-step logical tasks is a true test of reasoning. These challenges go beyond memorized facts—they require the model to break down steps, hold logic chains, and calculate accurately. It’s where we see the biggest gaps between models, especially on competition-level tasks.
We looked at benchmarks like AIME (a tough math contest for top students) and MathArena, a new Olympiad-style benchmark designed to push models to their limits. Here, the difference between reasoning “like a student” and thinking “like a solver” becomes clear.
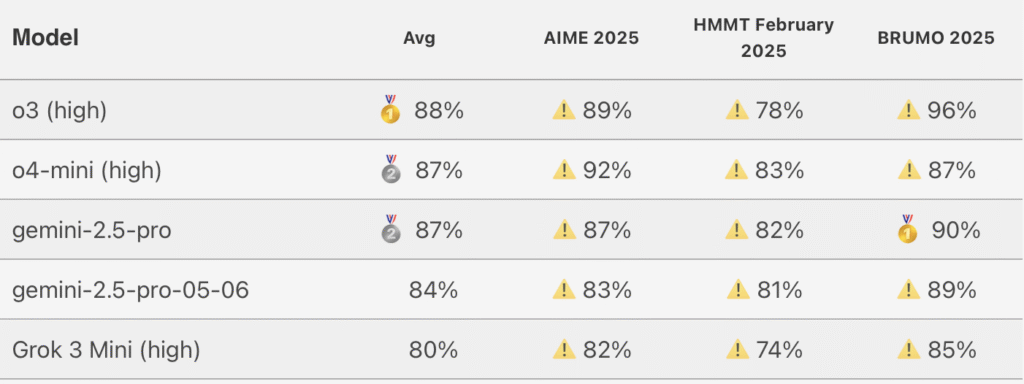
Winner: Gemini 2.5 Pro
Gemini stands out with 86.7% on AIME 2025, solving problems without any external tools. On MathArena, it scored 24.4%, while all others failed to break even 5%. That’s a massive gap—and it shows Gemini’s internal reasoning is world-class. It doesn’t just recall formulas; it thinks through them step by step.
Runner-Up: ChatGPT GPT-4.5 o3 (with tools)
With tool use (especially Python code execution), GPT-4.5’s o3 model dominates—scoring 98–99% on AIME. It’s superhuman with a calculator. Without tools, though, it trails Gemini in raw reasoning. If the problem requires math + action, o3 is unbeatable. But in pure thinking mode, Gemini currently leads.
Long Documents & Context Handling
When working with long texts—like academic papers, legal contracts, or full books—an AI’s context window becomes critical. It defines how much information the model can “see” at once. A larger window means fewer cutoffs, less chunking, and smoother, more accurate responses.
This is especially important for analysts, researchers, and developers who work with long-form content or entire codebases. Whether you’re feeding in a massive financial report or hundreds of chat logs, having more context leads to better summaries, insights, and continuity.
Winner: Gemini 2.5 Pro
Gemini leads with a jaw-dropping 1 million token context window—far beyond anything else available today. That’s the equivalent of multiple full books or long video transcripts fed in at once. It also retains coherence better across these huge inputs, making it ideal for cross-referencing documents, analyzing datasets, or building AI workflows that depend on deep memory.
Runner-Up: Claude 4 (Claude 3.7)
Claude offers a still-impressive 200K token context, perfect for single-document analysis or large code projects. It’s reliable for summarizing long PDFs, reviewing dense material, and maintaining clarity even deep into a conversation. For many real-world tasks, Claude is more than enough—and it handles large inputs gracefully without needing prompt engineering.
GPT-4.5
OpenAI’s GPT-4.5 supports up to 128K tokens—a significant step up from earlier GPT-4 models. It can handle book-length inputs and long-form chats well, but in ultra-large tasks (e.g. feeding in an entire wiki or codebase), it may need chunking. Still, for most business and personal needs, 128K is plenty.
Multimodal Tasks (Text + Image/Audio/Video)
Multimodal models can process and understand more than just text—images, audio, video, and combinations of these. This unlocks huge value for creatives, researchers, educators, and even developers working with real-world data.
Whether you’re uploading a graph, analyzing a diagram, transcribing audio, or combining different inputs into a unified answer, multimodality is becoming essential for “real-world AI.”
Winner: Gemini 2.5 Pro
Gemini is the only model in this comparison that handles all major modalities natively—text, images, audio, and video. You can feed it a chart, a photo, a video snippet, and some written context, and it’ll process them all together. This makes it uniquely suited for use cases like media summarization, academic research, or building AI tools that interact with multiple content formats at once.
Runner-Up: Claude 4 & GPT-4.5 (tie)
Both models accept text + image inputs, allowing users to upload screenshots, photos, or scanned documents. GPT-4.5 is known for accurate visual analysis (e.g. interpreting memes or charts), while Claude tends to be more conversational in how it interprets images. Neither model currently supports audio or video natively within the same prompt, but both cover the most common tasks well.
Grok 3
Grok supports image generation, which the others handle via external tools. You can prompt it to “draw” a scene or generate art. However, it doesn’t yet process multimodal inputs (like analyzing an image or video), so its capabilities remain more creative than analytical in this area.
Creative Writing & Tone
Not all AI outputs are created equal—especially when it comes to tone, style, and creativity. Whether you’re writing fiction, drafting ad copy, or just brainstorming fun ideas, the way an AI expresses itself can make a huge difference. Some models are polished and professional, while others feel more playful or personal.
Tone also affects how models respond over long conversations. Do they sound helpful, robotic, humorous, or overly formal? Each AI brings its own voice to the table—here’s how they compare.
Winner: Claude 4 (Claude 3.7 Sonnet)
Claude stands out with its emotionally intelligent and upbeat tone. It’s naturally verbose and friendly—great for fiction writing, brainstorming sessions, or roleplay. Many users say it feels like chatting with a helpful, creative friend. Claude also adds thoughtful elaboration to ideas, which makes it ideal for marketers, writers, and anyone wanting a collaborative co-writer with a warm personality.
Runner-Up: ChatGPT (GPT-4.5)
ChatGPT is more concise and controlled. It excels at mimicking tone, following prompts like “write in the style of Hemingway” or “use a professional business tone” with precision. While it’s not as naturally emotive as Claude, it’s extremely versatile and consistent—making it a strong choice for users who need well-formatted, targeted outputs across a wide range of styles.
Grok’s Unique Edge
Grok brings something different: humor, memes, and internet culture. It can respond with edgy, informal, or sarcastic tone when prompted—and sometimes even when not. While it’s not as polished in literary writing, Grok shines in satirical, trending, or unconventional writing tasks. Think social media posts, witty replies, or meme-worthy banter.
Agentic Behavior & Tool Use
Modern AI isn’t just about answering questions—it’s about doing things. The best models today can browse the web, run code, call external tools, and take multi-step actions. This ability to act like an autonomous assistant is called agentic behavior.
Winner: ChatGPT o3
The ChatGPT o3 variant leads here. It can independently decide to search the web, run Python code, or call toolswithout being told exactly how. Ask it to calculate something tricky or look up recent data, and it’ll do the steps on its own—like a real assistant with initiative. It’s fast becoming the gold standard for practical autonomy in consumer AI.
Runner-Up: Claude 4
Claude also supports tool use, especially in coding workflows (like in IDEs), and its Extended Thinking mode helps it reason step by step. However, it doesn’t yet act fully autonomously—you typically need to structure the prompt or integrate it via API to get agent-like behavior. Still, it’s a strong choice for thoughtful, guided automation.
Gemini 2.5 Pro
Gemini has powerful agentic capabilities under the hood—especially in enterprise settings through Google Cloud Vertex AI. It can plan and act across tools, and Google previewed “scheduled actions” and complex API flows. But for now, those features are mostly available in developer or enterprise environments, not directly through Bard or the public UI.
Real-Time Knowledge
Most large language models are trained on static data—so they can’t tell you what happened today without some form of live access. This is where real-time capability makes all the difference.
Winner: Grok 3
Grok is directly connected to X (formerly Twitter) and pulls in live data. That means it can answer real-time questionsabout trending topics, breaking news, and cultural chatter faster and more accurately than any other model. Want a recap of what’s blowing up online right now? Grok can give it to you instantly.
Perplexity
While not part of this comparison, it’s worth noting that Perplexity AI has emerged as a go-to tool for live-search-powered answers. It’s a search + LLM hybrid, and consistently provides real-time citations, making it great for news, academic updates, and fresh research queries.
So How to Choose the Right Model?
With AI models reaching unprecedented levels of capability in 2025, the best choice really depends on what you want to do. Each model brings a unique edge:
- If your focus is coding, debugging, or building software collaboratively, Claude 4 (Claude 3.7 Sonnet) offers top-tier performance—especially in extended, thoughtful workflows.
- For deep reasoning, scientific analysis, or combining long documents with images or data, Gemini 2.5 Pro leads with unmatched context handling and native multimodality.
- If you’re after a reliable all-round assistant—great for general knowledge, conversation, formatting, and easy API integration—ChatGPT with GPT-4.5 is your go-to.
- And if you need real-time knowledge, a more relaxed tone, or creative outputs with some edge, Grok 3 stands out for its live data access and personality.
There’s no single “best” model—only the best model for your task. That’s why using a multi-model assistant like Fello AI makes the most sense. It gives you access to all major models in one place, so you can tap Claude for coding, ChatGPT for summaries, Gemini for science, or Grok for trending content—without switching tools.
In 2025, the smartest move isn’t picking one AI. It’s picking an app that lets you use them all such as Fello AI.




