
OpenAI has just launched a brand-new series of GPT models—GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano—that promise major advances in coding, instruction following, and the ability to handle incredibly long contexts. In a tweet from Sam Altman (@sama), he explained that these models are designed for real-world utility and are available exclusively via the API. The announcement makes it clear: while ChatGPT will continue using an updated GPT‑4o model, these latest models push the boundaries for developers with even better performance.
The GPT‑4.1 series sets a new standard in various areas. With support for up to 1 million tokens of context—enough space to handle multiple long documents or even entire codebases—the new models are built to process extensive input and deliver relevant answers quickly. The series is geared toward applications that demand robust coding capabilities and nuanced instruction-following.
Developers and organizations can expect faster responses and lower costs. GPT‑4.1 mini and GPT‑4.1 nano, in particular, are designed to deliver improved latency and cost efficiency while still offering strong performance. With benchmarks demonstrating significant gains over previous models, OpenAI is clearly aiming to empower more sophisticated agentic applications.
Key Improvements and Capabilities
The GPT‑4.1 model family comes with several important enhancements compared to its predecessors. Here are some of the highlights:
Enhanced Coding Skills
GPT‑4.1 outperforms earlier models on coding benchmarks. It scores 54.6% on SWE‑bench Verified—a 21.4 percentage point improvement over GPT‑4o. This means the model is notably better at tasks such as exploring code repositories, generating code patches that run successfully, and even handling diff formats with fewer extraneous edits.
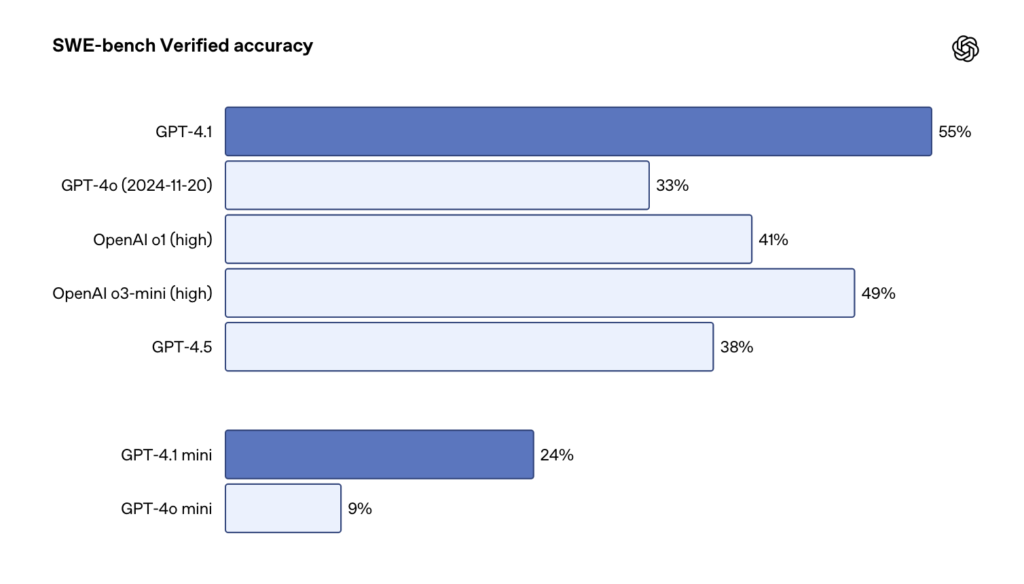
Instruction Following
The new models excel at following complex, multi-turn instructions. An internal evaluation using Scale’s MultiChallenge benchmark shows GPT‑4.1 scoring 38.3% compared to 27.8% for GPT‑4o. This improvement is critical when building agents that need to understand and act on multiple pieces of instruction sequentially.
Long-Context Processing
Perhaps the most eye-catching feature is the support for up to 1 million tokens per interaction. This extended context window gives the model the ability to “remember” and accurately process long documents or multiple data sources at once. In internal tests—such as Video‑MME and needle-in-a-haystack evaluations—the model demonstrated impressive accuracy even with vast amounts of input.
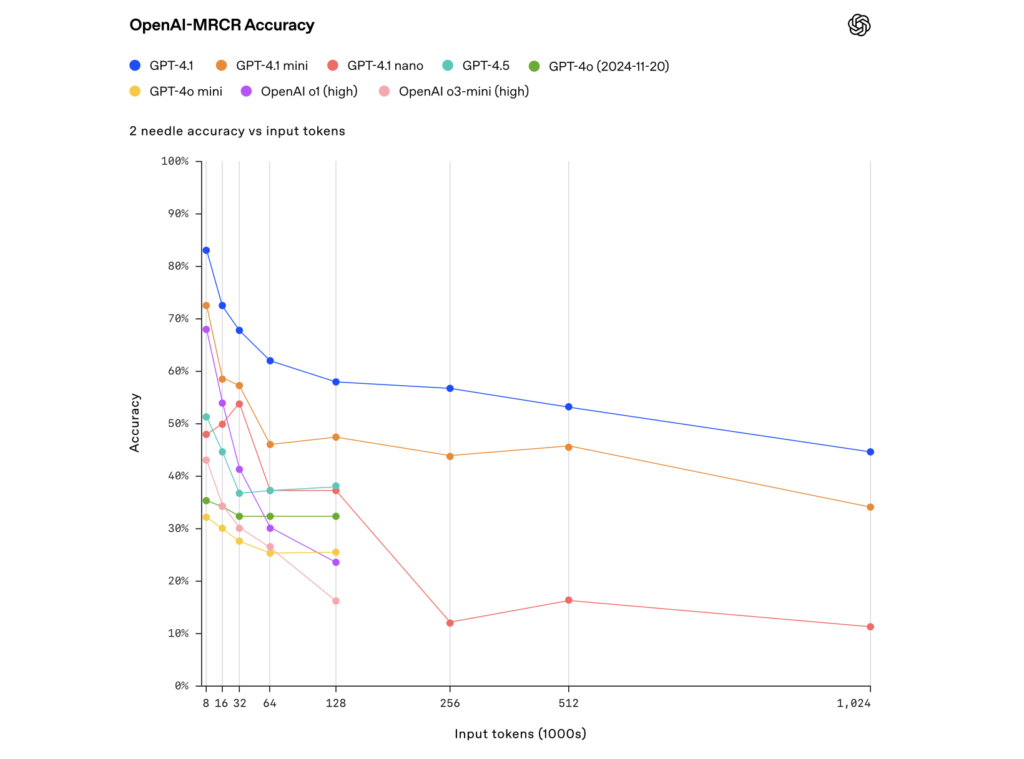
Improved Efficiency
While GPT‑4.1 offers top-tier performance on several benchmarks, the mini and nano variants trade a bit of accuracy for much lower latency and cost. For example, GPT‑4.1 nano is hailed as the fastest and cheapest option, making it ideal for tasks like classification and autocompletion.
These improvements are not just theoretical. OpenAI has tailored GPT‑4.1 based on direct feedback from the developer community, ensuring that everyday workflows—from automated code reviews to long document analysis—run smoother and faster.
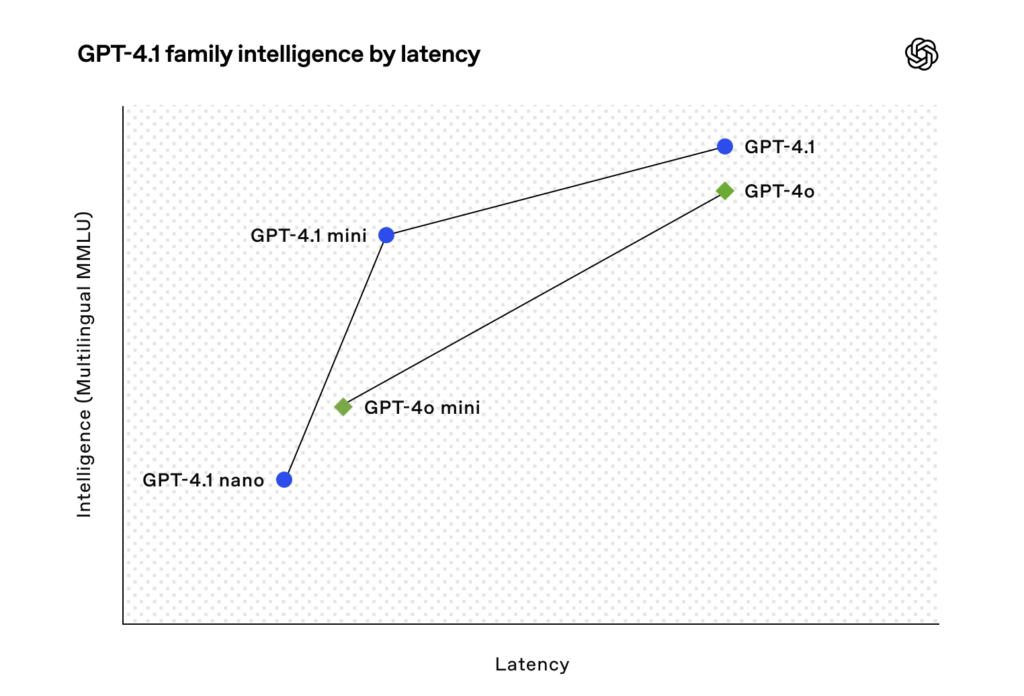
Benchmarks Performance
To put the improvements into perspective, here are some of the key performance figures and comparisons that OpenAI released:
Coding Capabilities
| Model | SWE‑bench Verified Accuracy | Polyglot Diff Accuracy (Whole/Diff) |
|---|---|---|
| GPT‑4.1 | 54.6% | 52% (whole) / 53% (diff) |
| GPT‑4o (2024‑11‑20) | 33.2% | 31% (whole) / 18% (diff) |
| GPT‑4.5 | 38% | 64% (whole) / 62% (diff) |
Note: The ‘diff’ format measures the model’s ability to follow diff formats for code changes, significantly reducing output length and costs.
Instruction Following
| Model | Internal API (Hard) | MultiChallenge Accuracy | IFEval Accuracy |
|---|---|---|---|
| GPT‑4.1 | 49.1% | 38.3% | 87.4% |
| GPT‑4o (2024‑11‑20) | 29.2% | 27.8% | 81.0% |
| GPT‑4.5 | 54.0% | 43.8% | 88.2% |
| GPT‑4.1 mini | 45.1% | 35.8% | 84.1% |
| GPT‑4.1 nano | 31.6% | 15.0% | 74.5% |
These numbers highlight the leaps in performance that GPT‑4.1 offers, especially in areas that matter for real-world applications such as multi-turn conversations and following detailed formatting instructions.
Long Context and Vision Evaluations
GPT‑4.1 also shows strong performance in tasks involving long-context and even vision-based questions. For example:
- Long Context Tasks:
In the OpenAI-MRCR evaluation (which tests the model’s ability to retrieve specific “needle” responses from a sea of similar content), GPT‑4.1 outperforms GPT‑4o with scores reaching 57.2% in a 128k token context scenario. - Vision Benchmarks:
In image-understanding tasks like MMMU and MathVista, GPT‑4.1’s scores are competitive, often exceeding those of GPT‑4o.
These benchmarks are supported by detailed evaluations and internal tests, reinforcing GPT‑4.1’s utility in scenarios ranging from detailed legal document reviews to complex coding tasks.
API Exclusivity
Beyond raw performance, GPT‑4.1’s release brings important business considerations for developers and enterprises. Here are some of the key details:
API-Only Access and Fine-Tuning Support
GPT‑4.1 is available exclusively via the API, meaning you won’t see it directly in the ChatGPT interface. Instead, ChatGPT continues to operate on an updated version of GPT‑4o, incorporating some of the improvements found in GPT‑4.1. This approach allows OpenAI to tailor GPT‑4.1 for specific developer needs and keep pushing performance with lower latency and cost.
OpenAI is also rolling out fine-tuning support for GPT‑4.1 and GPT‑4.1 mini. This upcoming feature will let organizations customize the models with their own data, ensuring that the responses match their desired tone, domain-specific terminology, and particular workflows. With integration in services like the Azure AI Foundry, businesses gain more control over versioning, security, and scalability.
Cost and Efficiency
The new models come with a detailed pricing structure designed to balance cost with performance:
| Model | Input Cost* | Output Cost* | Cached Input Cost* |
|---|---|---|---|
| GPT‑4.1 | $2.00 per 1M tokens | $8.00 per 1M tokens | $0.50 per 1M tokens |
| GPT‑4.1 mini | $0.40 per 1M tokens | $1.60 per 1M tokens | $0.10 per 1M tokens |
| GPT‑4.1 nano | $0.10 per 1M tokens | $0.40 per 1M tokens | $0.025 per 1M tokens |
*Pricing is based on typical input/output and cache ratios; expect further discounts when using the Batch API, which offers an additional 50% discount.
The efficiency improvements mean that, for example, GPT‑4.1 nano is the fastest and cheapest option available, ideal for scenarios like simple classification or code autocompletion. This pricing structure is designed to make these capabilities available to a wide range of applications—from small-scale startups to large enterprises.
Real-World Impact
Early testing by partners such as Windsurf, Qodo, Hex, Blue J, Thomson Reuters, and Carlyle has already shown the practical benefits of GPT‑4.1. From accelerating code review processes and reducing extraneous edits to handling complex legal and financial documents efficiently, these models are reshaping how developers build and deploy intelligent applications.
The real-world evaluations not only show enhanced performance but also underline substantial improvements in efficiency, making GPT‑4.1 a pivotal tool for building reliable, agentic software capable of independent decision-making and dynamic task management.
Conclusión
OpenAI’s GPT‑4.1 model series marks a significant evolution in AI—especially for developers whose work depends on robust coding, detailed instruction following, and processing long documents. With up to 1 million tokens of context, improved efficiency, and competitive pricing, these models open up new possibilities for a variety of real-world applications.
While GPT‑4.1 remains an API-only offering, its advanced features and upcoming fine-tuning support promise to revolutionize workflows in areas ranging from software engineering and legal analysis to data extraction and beyond. As developers continue to experiment and integrate these capabilities into their systems, GPT‑4.1 stands out as a bold step forward in the practical application of AI.
Stay tuned as the industry adapts to these breakthroughs and as more detailed analyses and user feedback come in. OpenAI’s focused improvements based on community input suggest that the GPT‑4.1 series is not only more powerful but also more aligned with the everyday needs of modern software development.




