
¿Estamos a las puertas de una revolución de la IA impulsada por un desvalido? DeepSeekuna startup china relativamente desconocida fundada en 2023, está causando sensación en la comunidad mundial de la IA con sus modelos vanguardistas de código abierto y unos costes de inferencia asombrosamente bajos.
A pesar de sus inicios discretos, DeepSeek ya se ha disparado a lo más alto de las listas de aplicacionesimpulsado por el recién publicado DeepSeek R1 modelo que muchos usuarios llaman "sorprendentemente bueno." Este artículo se adentra en la historia de DeepSeek, explora la tecnología que hay detrás de su rápido ascenso y examina los retos a los que se enfrenta mientras sacude el panorama chino y mundial de la IA.
La aplicación de DeepSeek plantea graves problemas de privacidad y seguridad al transmitir los datos de los usuarios, incluidos los registros de chat y las pulsaciones de teclas, a servidores en China. Estos datos están sujetos a las leyes chinas, que pueden obligar a las empresas a compartir información con el gobierno.
Para una alternativa más segura a la aplicación de DeepSeek, los usuarios pueden alojar sus modelos de código abierto localmente o utilizar plataformas de terceros que mantienen los datos en centros de datos occidentales, evitando los riesgos y la censura de los datos chinos.
El auge de DeepSeek
DeepSeek fue creada en mayo de 2023 por Liang Wenfengque anteriormente dirigió el High-Flyer fondo de cobertura cuantitativo. Dado que High-Flyer suscribe íntegramente DeepSeek, la empresa tiene libertad para llevar a cabo ambiciosas investigaciones sobre IA sin la presión habitual de generar beneficios a corto plazo. La empresa, con sede en Hangzhou (China), ha reunido a un joven equipo de licenciados de primer nivel de universidades chinas, que dan más importancia a las aptitudes técnicas que a la experiencia laboral convencional.
Desde el primer día, DeepSeek se ha guiado por dos objetivos fundamentales:
- Empujar hacia la Inteligencia Artificial General (AGI) de forma transparente y abierta
- Hacer más accesible la IA avanzada mediante precios agresivos y tecnología rentable
Este espíritu de código abierto y los precios disruptivos han puesto nerviosos a los operadores tradicionales, lo que ha llevado a potencias de la IA como OpenAI, Meta y las principales empresas tecnológicas chinas, como ByteDance, Tencent, Baidu y Alibaba, a reevaluar sus propios costes, estrategias y enfoques de investigación.
Hitos de DeepSeek
Desde su fundación en 2023, DeepSeek ha seguido una trayectoria constante de innovación, lanzando modelos que no sólo compiten con sus competidores más grandes, sino que a menudo los superan en coste y eficiencia. Desde su enfoque inicial en la codificación hasta sus avances en IA de propósito general, cada versión ha superado los límites de una manera única. He aquí un repaso de los hitos que han marcado la trayectoria de DeepSeek hasta la fecha.
Codificador de DeepSeek
Lanzado en Noviembre de 2023, Codificador de DeepSeek fue el primer lanzamiento importante de la empresa, dirigido a desarrolladores con un modelo de codificación de código abierto. En una época en la que las herramientas comerciales de generación de código eran cada vez más caras, ofrecía un alternativa gratuita y eficaz. El modelo podía generar, completar y depurar código, lo que le valió una rápida aceptación entre desarrolladores independientes y nuevas empresas. Su naturaleza de código abierto fomentó la personalización y la experimentación, lo que impulsó aún más su popularidad.
Este lanzamiento marcó la pauta de la misión de DeepSeek de democratizar el acceso a la IA. Aunque relativamente sencillo en comparación con modelos posteriores, DeepSeek Coder demostró que herramientas de IA accesibles podría ofrecer un gran rendimiento sin costes elevados, sentando las bases para futuras innovaciones.
DeepSeek LLM (67B)
Tras el éxito de su modelo de codificación, DeepSeek lanzó un Modelo lingüístico polivalente de 67B parámetros. A pesar de su menor tamaño en comparación con competidores como GPT-4, este modelo destacó en tareas como el resumen, el análisis de sentimientos y la IA conversacional. Al optimizar para eficacia de los parámetrosen muchas tareas igualaba o superaba a los modelos de mayor tamaño, al tiempo que mantenía una huella computacional reducida.
El LLM de DeepSeek demostró la capacidad de la empresa para desarrollar herramientas versátiles de IA que daba prioridad a la rentabilidad sin comprometer la calidad. También consolidó la reputación de DeepSeek como disruptor innovador capaz de ofrecer modelos competitivos con un presupuesto ajustado.
DeepSeek V2
Publicado en Mayo de 2024, DeepSeek V2 fue un punto de inflexión para la empresa, desencadenando un guerra de precios en el mercado chino de la IA. Al ofrecer un modelo lingüístico de alto rendimiento por una fracción del coste de sus competidores, DeepSeek obligó a grandes empresas como ByteDance, Tencent y Baidu a bajar sus precios. Este movimiento puso la IA avanzada al alcance de un mayor número de empresas y desarrolladores.
Desde el punto de vista técnico, la V2 ha mejorado notablemente con respecto a sus predecesoras, ofreciendo funciones mejoradas de generación de texto, análisis de sentimientos y mucho más. Su combinación de rendimiento y asequibilidad atrajo la atención de la comunidad mundial de la IA, demostrando que las empresas más pequeñas podían competir con los gigantes de la tecnología, que contaban con cuantiosos fondos.
DeepSeek-Coder-V2
A finales de 2024, DeepSeek volvió a sus raíces con DeepSeek-Coder-V2un modelo de codificación avanzado con 236.000 millones de parámetros y un ventana contextual de 128K fichas. Esta actualización le permitió abordar con impresionante precisión tareas de programación complejas, como el análisis de extensas bases de código o la resolución de intrincados retos de depuración.
Lo que hizo destacar a Coder-V2 fue su precio. A partir de $0,14 por millón de fichas de entrada y $0,28 por millón de fichas de salidase convirtió en uno de los herramientas de codificación rentables disponibles. El modelo cimentó la reputación de DeepSeek de proporcionar soluciones de IA de alta calidad a una fracción del coste exigido por la competencia.
DeepSeek V3
El lanzamiento de DeepSeek V3 a finales de 2024 marcó el paso más avanzado de la empresa hasta la fecha, introduciendo 671.000 millones de parámetros y dos innovaciones revolucionarias:
- Mezcla de expertos (MDE): Sólo se activa 37.000 millones de parámetros por tareareduciendo drásticamente los costes computacionales y manteniendo alto rendimiento.
- Atención latente multicabeza (MLA): Aumento de la capacidad del modelo para procesar relaciones matizadas y gestionar múltiples entradas simultáneamente, lo que lo hace muy eficaz para tareas que requieren profundidad contextual.
Aunque eclipsado por los lanzamientos más destacados de OpenAI y Meta, DeepSeek V3 se ha ganado silenciosamente el respeto de los círculos de investigación por su combinación de escala, rentabilidad e innovación arquitectónica. También sentó las bases técnicas del logro más importante de DeepSeek hasta la fecha: DeepSeek R1..
DeepSeek R1
DeepSeek ha dado su paso más audaz con DeepSeek R1lanzada el 21 de enero de 2025. Este modelo de IA de código abierto se ha convertido en el desafío más serio de la startup a los gigantes tecnológicos estadounidenses, debido a su formidable capacidad de razonamiento, sus menores costes operativos y sus funciones fáciles de desarrollar.
Características principales
- Arquitectura mixta de expertos (MDE)
R1 amplía el concepto de MoE visto por primera vez en V3, activando sólo las subredes necesarias para una consulta específica. Esto permite un alto rendimiento en tareas exigentes sin devorar recursos de hardware. - Aprendizaje por refuerzo puro (RL)
Mientras que muchos modelos de IA de la competencia se basan en gran medida en el ajuste fino supervisado, R1 incorpora una sólida canalización RL: aprender a razonar a través de la iteración constante y la retroalimentación, en lugar de depender únicamente de conjuntos de datos etiquetados. - Ventana contextual masiva
Capaz de procesar hasta 128.000 tokens en una petición, R1 gestiona fácilmente tareas extensas como revisiones complejas de código, análisis de documentos legales o problemas matemáticos de varios pasos. - Alta capacidad de producción
El modelo puede generar hasta 32.000 fichas a la vez, lo que lo hace ideal para redactar informes en profundidad o diseccionar extensos conjuntos de datos. - Rentabilidad sin precedentes
El coste de la inferencia de DeepSeek R1 se estima en sólo una pequeña fracción -alrededor de 2%- de lo que las organizaciones pagan por modelos comparables de OpenAI. Tanto para los desarrolladores en solitario como para las empresas, esto puede cambiar las reglas del juego.
Indicadores de rendimiento
DeepSeek R1 ha registrado puntuaciones notables en pruebas matemáticas y lógicas, superando a OpenAI's o1 Preview con una puntuación de 91,6% en el benchmark MATH y 52,5% en AIME. Aunque iguala a la o1 de OpenAI en muchas tareas de codificación, sigue estando ligeramente por detrás de Claude 3.5 Sonnet en determinados escenarios de código especializado. Sin embargo, la capacidad de R1 para mostrar un razonamiento detallado paso a paso destaca como una gran ventaja, especialmente para la depuración, los usos educativos y la investigación.
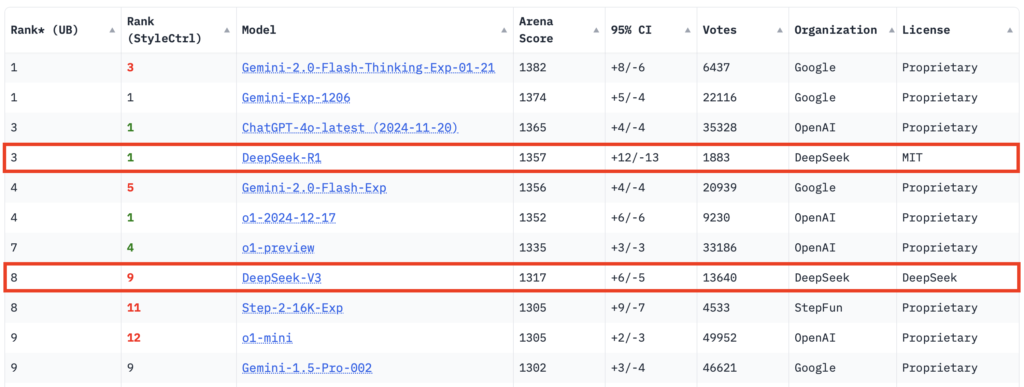
Quizá lo más revelador de su éxito sea la adopción por parte de los usuarios. R1 llevó a DeepSeek al primer puesto de la App Store el 26 de enero de 2025, y rápidamente alcanzó el millón de descargas en Play Store. Los usuarios citan la función "DeepThink + Web Search", introducida recientemente, como uno de sus atributos más destacados, un área en la que ni siquiera OpenAI ha conseguido ponerse al día.
Innovaciones de DeepSeek
Ambos DeepSeek V3 y R1 aprovechar la Mezcla de expertos (ME) arquitectura, que activa sólo un subconjunto de su masiva 671.000 millones de parámetros. Es como desplegar cientos de microexpertos especializados que intervienen cuando se necesitan sus conocimientos. Este diseño garantiza la eficiencia computacional sin merma de la calidad del modelo.
La adopción por parte de DeepSeek de un aprendizaje por refuerzo puro (RL) lo distingue aún más. Los modelos aprenden y mejoran de forma autónoma a través de continuos circuitos de retroalimentación que permiten la autocorrección y la adaptabilidad. Este mecanismo mejora significativamente su capacidad de resolución de problemasespecialmente para tareas que requieran razonamiento profundo y análisis lógico.
Más allá del ME, Atención latente multicabeza (MLA) aumenta la capacidad de los modelos para procesar varios flujos de datos a la vez. Al distribuir la atención entre varias "cabezas de atención", pueden identificar mejor relaciones contextuales y manejar entradas matizadas, incluso cuando se procesan decenas de miles de tokens en una sola solicitud.
Las innovaciones de DeepSeek también se extienden a modelo de destilacióndonde los conocimientos de sus modelos más grandes se transfieren a versiones más pequeñas y eficientes, tales como Destilador DeepSeek-R1. Estos modelos compactos conservan gran parte de la capacidad de razonamiento de sus homólogos de mayor tamaño, pero requieren muchos menos recursos informáticos, lo que hace más accesible la IA avanzada.
Reacciones de la comunidad de IA
Varias figuras destacadas de la IA han opinado sobre el potencial disruptivo de DeepSeek R1:
- Dra. Sarah ChenDirector de Investigación en Inteligencia Artificial de Stanford, señaló que DeepSeek R1 desafía la idea de que la IA de alto rendimiento requiere inmensos recursos informáticos. Al ofrecer resultados de primer nivel por una fracción del coste, DeepSeek ha abierto la puerta a la IA de alto rendimiento. democratizar el acceso a las tecnologías avanzadas de IA en todos los sectores.
- Profesor James Miller del MIT, destacó el marco de aprendizaje por refuerzo y las capacidades de búsqueda avanzada de DeepSeek R1 como marcadores de un nuevo estándar en metodologías de entrenamiento de IA. Sugiere que estas innovaciones pueden empujar a toda la industria a replantearse cómo se entrenan y optimizan los modelos de IA.
- Alex Zhavoronkovdirector general de Insilico Medicine, elogió la inspiración biológica detrás de la estructura de aprendizaje por refuerzo de DeepSeek R1. Lo describió como un importante paso adelante en la autoevaluación lógica y la adaptabilidad, con implicaciones que van mucho más allá de los actuales paradigmas de investigación de la IA.
- Marc Andreessen, cofundador de Andreessen Horowitz, describió DeepSeek R1 como "El momento Sputnik de la IA" y uno de los avances más asombrosos e impresionantes que ha visto nunca. También elogió su naturaleza de código abiertocalificándolo de "profundo regalo para el mundo". Este nivel de entusiasmo por parte de una destacada figura de la tecnología subraya la importancia del modelo y su impacto en la industria.
Al mismo tiempo, hay escépticos. Se han planteado dudas sobre posibles sesgos en los datos de entrenamiento y implicaciones geopolíticas debido a los orígenes chinos de DeepSeek. Aunque su ética del código abierto es ampliamente elogiado, algunos se preocupan por obligaciones reglamentarias y el impacto de la censura china en la adopción mundial.
Modelo de negocio y asociaciones
La estrategia de financiación de DeepSeek no se parece a la de la mayoría de las empresas de IA. La empresa está financiada íntegramente por High-Flyerun exitoso fondo de cobertura cuantitativo fundado por Liang Wenfeng. Este acuerdo único permite a DeepSeek operar sin las presiones de las demandas de los accionistas o el cumplimiento de los agresivos hitos de la Serie A.
Liberada de las limitaciones típicas de las empresas de capital riesgo, DeepSeek puede priorizar investigación e innovación a largo plazo sobre la comercialización inmediata. Hasta ahora, la empresa no ha mostrado urgencia por buscar oportunidades comerciales a gran escala, sino que se ha centrado en perfeccionar sus modelos de IA e impulsar la innovación.
Una de las características más destacadas de DeepSeek es su precios de API increíblemente bajoshaciendo que la IA avanzada sea mucho más accesible. Por ejemplo, R1 cuesta desde $0,55 por millón de fichas de entrada y $2,19 por millón de fichas de salidaEl precio de DeepSeek es mucho más barato que el de OpenAI u otros laboratorios de IA estadounidenses. Esta asequibilidad ha ayudado a DeepSeek a hacerse un hueco entre promotores preocupados por los costes, startups, y pequeñas empresas que, de otro modo, tendrían dificultades para costearse herramientas de IA de última generación. Al ofrecer soluciones tan asequibles, DeepSeek se ha posicionado como una alternativa viable a plataformas propietarias más caras.
DeepSeek asociación con AMD también ha desempeñado un papel fundamental en su éxito. Al utilizar GPU AMD Instinct y software ROCM de código abiertoDeepSeek ha sido capaz de entrenar sus modelos, incluyendo V3 y R1, en costes extraordinariamente bajos. Esta colaboración desafía la dependencia del sector de las GPU de gama alta de NVIDIA o las TPU de Google, demostrando que un entrenamiento eficaz no requiere acceder al hardware más caro. La colaboración es una prueba de que DeepSeek se centra en innovación rentable y su capacidad de aprovechar las colaboraciones estratégicas para superar las limitaciones del hardware.
En conjunto, estos factores subrayan la capacidad de DeepSeek para equilibrar asequibilidad, excelencia técnica e independencia, lo que le permite competir eficazmente con competidores más grandes y mejor financiados, manteniendo al mismo tiempo la accesibilidad en primer plano.
Panorama competitivo
DeepSeek se ha posicionado como un disruptor en el mercado de la IA, enfrentándose tanto al laboratorios de IA estadounidenses más grandes del mundo y Los gigantes tecnológicos chinos.
Enfrentarse a OpenAI, Google y Meta
OpenAI, Google y Meta cuentan con vastos recursos, una reputación consolidada y acceso a algunos de los mejores sistemas de información del mundo. los mejores talentos del mundo en IA. Estas empresas operan con presupuestos multimillonarios, lo que les permite realizar grandes inversiones en hardware, investigación y marketing. DeepSeek, en cambio, adopta un enfoque más enfoque específicocentrándose en innovación de código abierto, ventanas contextuales más largas, y reducción drástica de los costes de utilización.
Los modelos de DeepSeek, como R1ofrecen un rendimiento comparable o superior en áreas específicas como las matemáticas y las tareas de razonamiento, a menudo en una fracción del coste. Esto convierte a DeepSeek en una alternativa atractiva para las organizaciones que consideran que las herramientas de IA patentadas son demasiado caras o restrictivas. Al hacer hincapié en la accesibilidad y la transparencia, DeepSeek desafía la narrativa de que sólo los jugadores de gran presupuesto pueden ofrecer... soluciones de IA de última generación.
La disrupción de los gigantes tecnológicos chinos
El auge de DeepSeek también ha perturbado a líderes tecnológicos chinos como ByteDance, Tencent, Baidu, y Alibaba. Estas empresas están profundamente arraigadas en la economía china. Ecosistema de IAa menudo respaldado por recursos informáticos a nivel estatal. Sin embargo, DeepSeek filosofía de código abierto y estrategia agresiva de precios le han permitido hacerse un hueco único. Al ofrecer modelos rentables y eficientes, DeepSeek ha obligado a estas empresas a reevaluar sus propias estrategias de precios y desarrollo.
La capacidad de DeepSeek para competir con estos gigantes, fuertemente financiados, subraya su condición de formidable contrincante tanto dentro de China como en la escena mundial.
La iniciativa Open R1
Un testimonio de la creciente influencia de DeepSeek es la publicación de Hugging Face Iniciativa Open R1un ambicioso proyecto que pretende reproducir en su totalidad el Canal de entrenamiento de DeepSeek R1. Si tiene éxito, esta iniciativa podría permitir a los investigadores de todo el mundo adaptar y perfeccionar los modelos tipo R1acelerando aún más la innovación en el ámbito de la IA.
Aunque esto pone de relieve el impacto de la estrategia de código abierto de DeepSeek, también expone posibles vulnerabilidades. Al abrir sus modelos a la comunidad de IA, DeepSeek invita a competencia de los que se basan en sus avances. Sin embargo, esta apertura es un movimiento deliberado para democratizar el desarrollo de la IA y fomentar la colaboración, una filosofía que diferencia a DeepSeek de otras empresas más centradas en la propiedad.
Gracias a sus precios disruptivos, su compromiso con el código abierto y sus capacidades competitivas, DeepSeek ha logrado prosperar en un mercado dominado por los gigantes tecnológicos, demostrando que innovación y eficacia puede rivalizar incluso con los presupuestos más elevados.
El futuro de DeepSeek
El rápido ascenso de DeepSeek viene acompañado de retos que podrían condicionar su futuro. Control de las exportaciones estadounidenses restringir el acceso a las GPU avanzadas, creando un calcular la diferencia que podría dificultar su capacidad para escalar modelos como el R1. Aunque su Arquitectura del ME maximiza la eficiencia, competir con empresas que tienen acceso a hardware de vanguardia puede resultar más difícil con el tiempo.
DeepSeek también se enfrenta a obstáculos en percepción del mercado. Para ganarse la confianza internacional, debe demostrar sistemáticamente su fiabilidad, especialmente en las implantaciones de nivel empresarial. Mientras tanto, la un panorama de IA en rápida evolución significa que competidores como OpenAI o Meta podrían superarla con nuevas innovaciones. Además, operar bajo Marcos reglamentarios chinos impone restricciones de contenido que pueden limitar su atractivo en los mercados abiertos.
A pesar de estos retos, DeepSeek se centra en su DeepThink + Búsqueda web que permite realizar búsquedas en tiempo real, la posiciona como un competidor único. La empresa también podría mejorar ajuste del aprendizaje por refuerzoDesarrollar modelos sectorialesy forjar nuevas asociaciones mundiales para ampliar sus capacidades. Si consigue sortear estos obstáculos, DeepSeek tiene potencial para seguir siendo una fuerza disruptiva en el campo de la IA.
Reflexiones finales
En pocos años, DeepSeek ha pasado de ser una desconocida startup impulsada por la investigación en Hangzhou a una disruptor global en IAque sacude a gigantes del sector como OpenAI, Meta y Google. Al combinar colaboración de código abiertoarquitecturas innovadoras como Mezcla de expertos (ME)y unos precios muy competitivos, DeepSeek ha redefinido nuestra forma de concebir el desarrollo de la IA. Modelos como DeepSeek V3 y el innovador DeepSeek R1 demuestran que el éxito de la IA no siempre requiere presupuestos multimillonarios. En cambio, la eficiencia, la adaptabilidad y las asociaciones estratégicas pueden ofrecer resultados que rivalicen incluso con los modelos más caros.
Lo que hace aún más extraordinario el viaje de DeepSeek es la conmoción que ha generado en la comunidad de la IA. Expertos e investigadores del sector han manifestado su asombro ante el hecho de que una empresa más pequeña haya conseguido competir -e incluso superar- algunos de los modelos más avanzados desarrollados por organizaciones mucho mejor financiadas.
DeepSeek no muestra signos de desaceleración. Su reciente lanzamiento de DeepThink + Búsqueda webque permite búsquedas en línea en tiempo real, la sitúa por delante incluso de OpenAI en algunas capacidades. De cara al futuro, es probable que la empresa se centre en:
- Perfeccionamiento de los canales de aprendizaje por refuerzo para mejorar aún más la capacidad de razonamiento.
- Desarrollo de modelos sectoriales a medida para ámbitos como la sanidad, las finanzas y la educación.
- Forjar nuevas asociaciones con proveedores mundiales de hardware para superar la brecha informática creada por las restricciones a la exportación.
Como la adopción de DeepSeek R1 por parte de los usuarios sigue aumentando, la empresa está forzando a los actores establecidos de la IA a adaptarse. Se ha demostrado que eficacia e innovación pueden rivalizar con la potencia de cálculo bruta y presupuestos inmensos, sentando un nuevo precedente de lo que es posible en la IA.
Si DeepSeek puede mantener este impulso en medio de retos como restricciones geopolíticas, intensa competencia, y cuestiones de confianza del mercado aún está por ver. Sin embargo, una cosa está clara: DeepSeek ya ha demostrado ser una fuerza a tener en cuentaEl objetivo es ampliar los límites de la inteligencia artificial y potenciar a las pequeñas empresas, los investigadores y los desarrolladores de todo el mundo.
Para quien esté intrigado por la innovación de bajo coste puede revolucionar los flujos de trabajo de la IADeepSeek es un nombre que merece la pena seguir. Es muy posible que la próxima oleada de avances transformadores surja de esta ambiciosa empresa en horas bajas.




