
Today, Anthropic introduced Claude 3.7 in a bid to take the lead in the fast-moving AI race. This new release marks the company’s latest effort to stand out among competitors, offering a tool designed to handle both quick answers and more challenging tasks.
It’s not even a week since Elon Musk’s xAI introduced Grok 3—a model designed to deliver superior reasoning and performance—while DeepSeek has been making waves with its efficient V3/R1 models. Even OpenAI is iterating on its offerings with models like GPT o3-mini and teasing GPT-4.5, emphasizing competitive pricing and improved stability.
Now, Anthropic has entered the next stage of this AI arms race with Claude 3.7 Sonnet, a hybrid reasoning model designed to outperform previous versions in coding, general intelligence, and real-world task execution. It represents a shift toward AI that can dynamically adjust its level of reasoning, making it a versatile tool for both quick answers and deep analytical work.
What Is Claude 3.7 Sonnet?
Claude 3.7 Sonnet is Anthropic’s most advanced model to date, marking a significant improvement over Claude 3.5 Sonnet. What makes it stand out is its ability to seamlessly switch between quick responses and extended, step-by-step reasoning.
Claude 3.7 Sonnet functions as both an ordinary LLM and a reasoning model in one. Users can choose when they want the model to respond instantly and when they want it to take more time to think before answering. In its standard mode, it represents an upgraded version of Claude 3.5 Sonnet, while in extended thinking mode, it self-reflects before answering, improving performance on math, physics, instruction-following, and coding tasks.
Another major improvement is in coding. Claude 3.7 Sonnet demonstrates significant advancements in front-end development, debugging, and full-stack implementation. Its reasoning capabilities allow it to analyze and modify complex codebases more effectively than previous versions. It also supports up to 128K tokens, allowing it to process and reason over much larger bodies of text than many competitors.
Additionally, Anthropic has worked on improving the model’s safety and usability. Claude 3.7 Sonnet has reduced unnecessary refusals by 45%, making it more reliable while still adhering to ethical guidelines. The pricing remains the same as its predecessor: $3 per million input tokens and $15 per million output tokens, making it a cost-effective solution for high-quality AI-driven reasoning and problem-solving.
Claude 3.7 Sonnet is now available on Claude.ai (web, iOS, and Android), Anthropic’s API, Amazon Bedrock, and Google Cloud’s Vertex AI. Coming to Fello AI within couple of days.
Comparison of Claude 3.7 to Other Models
Anthropic has designed Claude 3.7 Sonnet to be highly competitive across multiple domains. Compared to OpenAI’s o3-mini and DeepSeek R1, Claude 3.7 Sonnet is better at handling vague, ambiguous questions, producing structured, logical responses. Developers at Cursor, Cognition, Vercel, and Canva report that Claude 3.7 Sonnet outperforms all models in real-world software engineering tasks.
Anthropic has designed Claude 3.7 Sonnet to be highly competitive across multiple domains, surpassing other leading AI models in various capabilities.
Benchmark Performance
Claude 3.7 Sonnet has demonstrated significant advancements in reasoning, instruction-following, and coding. Its improved processing capabilities make it particularly effective at handling complex queries, ambiguous prompts, and multi-step problem-solving.
In benchmark tests:
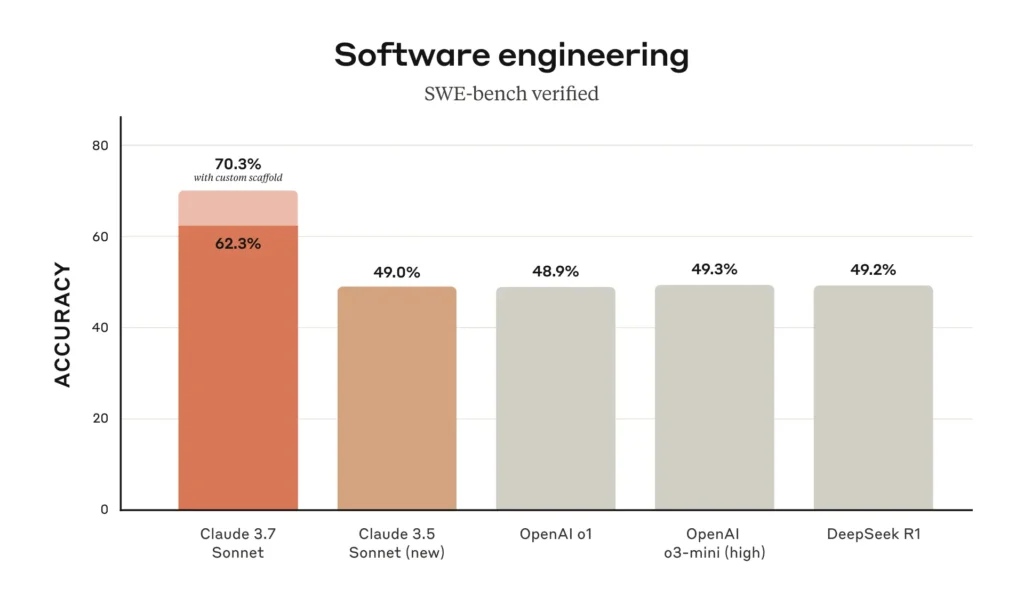
- SWE-bench Verified (real-world coding tasks):
- Claude 3.7 Sonnet: 63.7%
- OpenAI o3-mini: 49.3%
- DeepSeek R1: 55%
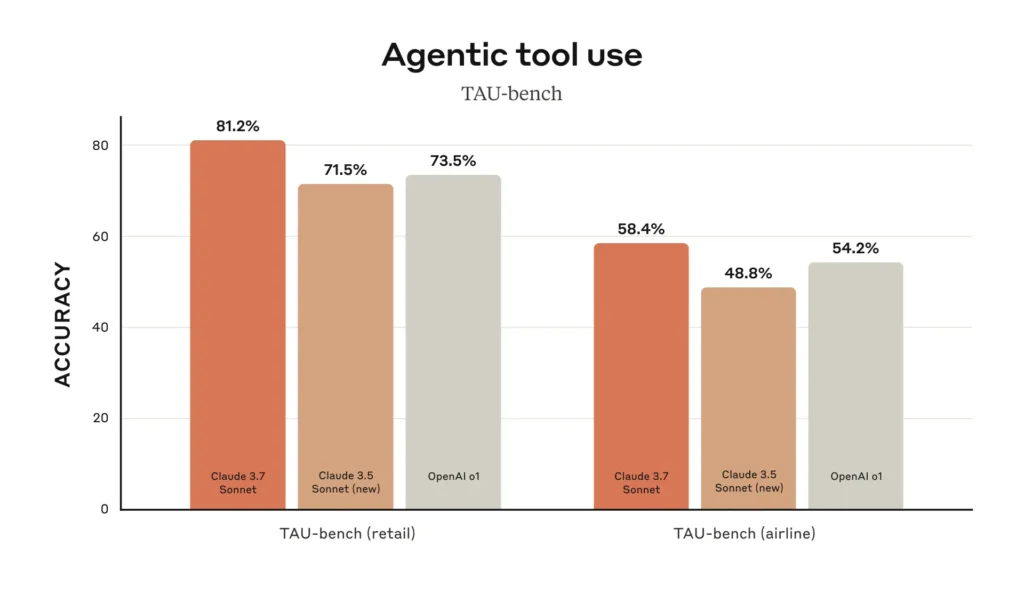
- TAU-bench (AI agent performance on complex real-world tasks):
- Claude 3.7 Sonnet: 81.2%
- OpenAI o1: 73.5%
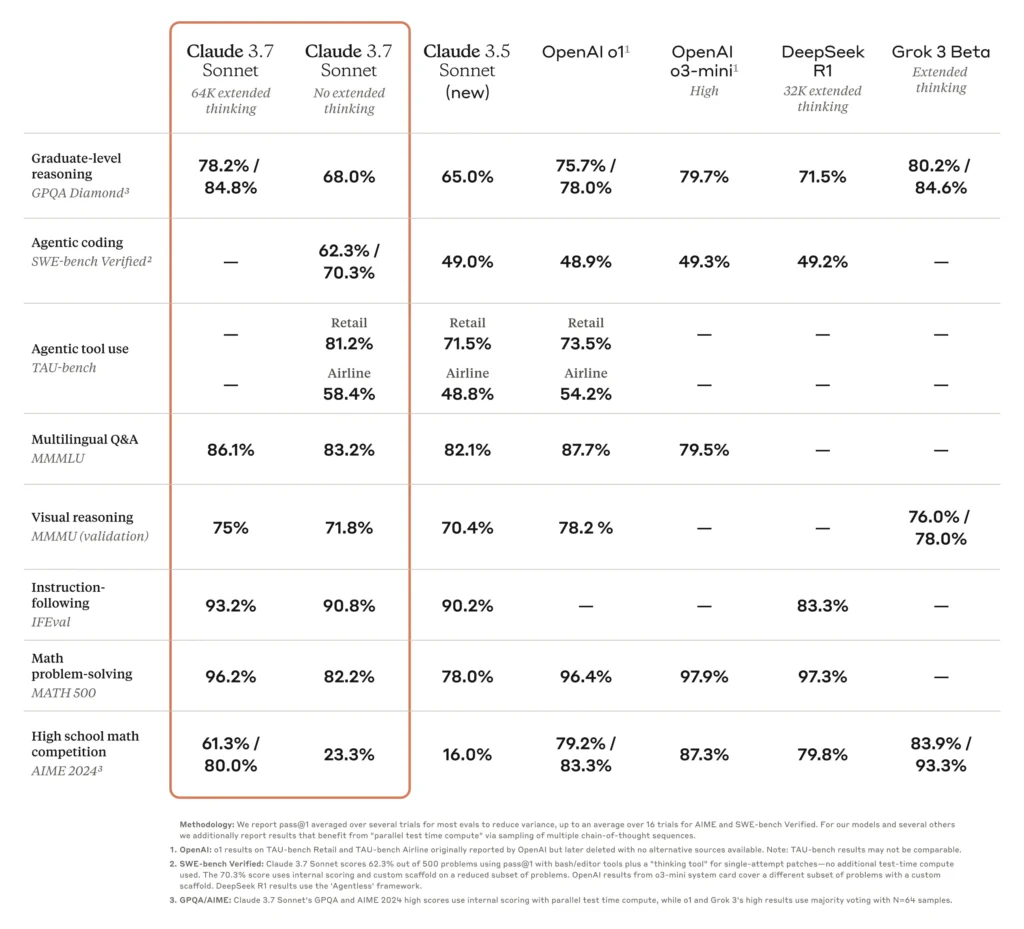
These benchmarks demonstrate Claude 3.7 Sonnet’s state-of-the-art performance in areas crucial for real-world AI applications, especially in software engineering and reasoning-heavy tasks.
Handling of Complex Queries
Compared to OpenAI’s o3-mini and DeepSeek R1, Claude 3.7 Sonnet excels in responding to vague or ambiguous prompts with logical, structured answers. It better understands the intent behind queries and provides more refined, accurate responses. This makes it particularly useful for business applications, customer support, and advanced research tasks where clear, context-aware responses are essential.
Context Length
Claude 3.7 Sonnet comes with a 128K token context window, giving it an edge in processing and analyzing large documents more efficiently than many competitors. This expanded capacity allows for deeper understanding and better retention of complex information.
With this, Claude excels in tasks like legal and financial document analysis, summarizing scientific research and academic papers, and handling large codebases for software development. It’s also well-suited for detailed content creation, making it a powerful tool for writers and creatives.
Flexible Thinking Mode
Another key advantage is Claude 3.7 Sonnet’s ability to switch between rapid response mode and extended thinking mode, making it more flexible than models that are purely optimized for reasoning. Its 128K token window also allows it to handle larger documents and longer contextual references better than most competitors.
Claude 3.7 Sonnet allows users to choose between instant answers and extended reasoning. This flexibility provides a unique advantage:
- Standard mode for quick, real-time interactions.
- Extended thinking mode for deeper analysis, enhanced accuracy, and complex decision-making.
This dual approach ensures that users can optimize performance based on their specific needs, whether speed or depth is the priority.
Real-World Implementation
Developers from Cursor, Cognition, Vercel, and Canva report that Claude 3.7 Sonnet consistently outperforms other models in software engineering tasks. Its 128K token context window allows for more coherent planning and execution of full-stack updates, making it a powerful tool for teams handling complex projects.
For debugging, Claude efficiently traces errors across multiple files, suggests optimized fixes, and refactors legacy code. But can AI replace human intuition? While it speeds up troubleshooting, it lacks the deep understanding of system architecture and security best practices that experienced developers bring. AI is a tool, not a replacement.
When it comes to production-ready code, Claude follows strong design principles and produces cleaner, more scalable solutions. Yet, should we fully trust AI-generated code? It might not catch all edge cases or security risks, requiring human oversight to ensure quality and reliability.
OpenAI’s o3-mini is a solid budget option but falls short in multi-step reasoning and handling large-scale projects. The real question is—does cutting costs on AI tools lead to higher technical debt? For companies prioritizing long-term efficiency, Claude 3.7 Sonnet is the smarter investment, provided it’s used to enhance, not replace, developer expertise.
Claude Code
With the growing demand for AI-assisted coding, Anthropic has introduced Claude Code, a command-line AI coding assistant designed to automate complex software engineering workflows. Unlike cloud-dependent AI tools, Claude Code operates directly in the terminal, minimizing latency and allowing developers to interact with AI while maintaining full control over their codebase.
Features and Capabilities
Claude Code supports over 25 programming languages and integrates natively with GitHub, GitLab, and essential developer tools like Node.js, ripgrep, and CLI-based version control. Developers can use it to edit files, refactor code, debug across multiple files, and generate test cases. Benchmarks indicate that it can efficiently handle codebases exceeding 1 million lines of code, making it well-suited for large-scale software development.
One of its key strengths is its ability to automate Git operations. Developers can create commits, generate pull requests, resolve merge conflicts, and search through Git history—all through simple natural language commands. Internal tests have shown that this feature alone reduces time spent on code reviews and debugging by 60%. Claude Code also supports real-time linting, security vulnerability detection, and integration testing, improving overall code quality.
Performance and Productivity Gains
Early testing across 300+ developer teams has shown that Claude Code accelerates coding tasks by an average of 45 to 60 minutes per session, leading to a 25% increase in developer productivity. Its 128K token context window enables it to understand complex project structures, reducing the need for developers to manually specify context or load files.
Security is another key focus. Claude Code includes a tiered permission system, requiring explicit user approval for executing shell commands or modifying files. It also enforces prompt injection protections, input sanitization, and API-level security controls, reducing risks associated with AI-assisted development. For enterprise users, Claude Code runs entirely within local environments, ensuring that sensitive codebases remain secure.
Future Improvements
As Claude Code evolves, Anthropic plans to enhance tool execution reliability, support long-running commands, and improve terminal rendering. Additionally, updates will refine Claude’s ability to self-assess its capabilities, making it a more efficient and intuitive assistant for developers. With its blend of automation, security, and deep code understanding, Claude Code is positioned to become an essential tool for modern software teams.
Conclusion
The AI industry is experiencing unprecedented growth, with companies rapidly introducing advanced models to gain a competitive edge. Anthropic’s release of Claude 3.7 Sonnet exemplifies this trend, offering a hybrid reasoning model that combines quick responses with in-depth analytical capabilities. This innovation allows users to tailor the model’s reasoning process to their specific needs, enhancing versatility in applications ranging from coding to complex problem-solving.
Simultaneously, other industry leaders are accelerating their AI developments. Elon Musk’s xAI has unveiled Grok 3, claiming superior performance in areas like mathematics and coding. DeepSeek has introduced efficient V3/R1 models, challenging established norms with cost-effective solutions. OpenAI continues to iterate with models such as GPT o3-mini and the anticipated GPT-4.5, focusing on competitive pricing and enhanced stability.
This intense competition fosters continuous innovation, ultimately benefiting users by providing a diverse array of AI tools tailored to various needs. As models become more sophisticated, the emphasis on hybrid reasoning, user adaptability, and ethical AI deployment is likely to intensify. The convergence of competition and innovation ensures that AI technology evolves to meet the complex demands of modern applications, positioning users as the ultimate beneficiaries in this rapidly advancing landscape.




