
On May 8, 2026, Baidu released ERNIE 5.1, a new flagship model that is already shaking the leaderboards. ERNIE 5.1 hit #4 globally on the LMArena Search Arena with a score of 1223, becoming the only Chinese model in the global top 10 for search performance. Alibaba followed weeks later with its Qwen3.7-Max flagship, the highest-placed Chinese model on the Artificial Analysis Intelligence Index. It also reached global rank 14 on the LMArena text leaderboard, the highest position any Chinese lab has held in that category.
What is most striking is how ERNIE 5.1 was built. It compresses total parameters to roughly one third of ERNIE 5.0, cuts active parameters in half, and uses only about 6% of the pre-training compute spent on comparable frontier models. Baidu is openly framing it as a parameter-efficiency play, not a scale-up.
In this article we walk through what changed, the benchmarks, the new training infrastructure behind it, real-world performance across writing, math, search, spreadsheets, and code, and how it stacks up against DeepSeek V4 Pro, Claude Opus 4.6, and Gemini 3.1 Pro.
What ERNIE 5.1 Actually Is
ERNIE 5.1 is not a from scratch model. It is the best performing sub-network extracted from the elastic sub-model matrix that Baidu trained when building ERNIE 5.0 (a 2.4 trillion parameter unified multimodal foundation model). Instead of running a brand new pre-training campaign at full scale, Baidu reused that existing matrix, picked an optimal slice, and continued training on top.
The result is a model with roughly 800 billion total parameters, around one third of ERNIE 5.0, and approximately one half the active parameters at inference time. Despite being substantially smaller than its predecessor, ERNIE 5.1 outperforms ERNIE 5.0 across most benchmarks and approaches the strongest closed-source models on several axes.
Release timing is also notable. ERNIE 5.0 launched in late January 2026. ERNIE 5.1 follows roughly three months later, a release cadence closer to OpenAI and Anthropic than to the typical Chinese release schedule.
A Brief History of ERNIE
ERNIE has been around longer than most of the current frontier names. Baidu started the ERNIE line in 2019 as an NLP research project (the name stands for Enhanced Representation through Knowledge Integration), and it predates the modern wave of consumer chatbots by several years. The trajectory is worth understanding because the strengths and weaknesses on display in 5.1 are not new, they have been visible across the full release history.
ERNIE Bot (March 2023) was Baidu’s answer to ChatGPT and the first ERNIE version most people outside China encountered. The launch event was widely viewed as underwhelming. Baidu showed pre-recorded demos rather than a live model, and early hands-on reviews flagged the model as noticeably behind GPT-3.5 on reasoning and English language tasks. It was, however, the first major Chinese language LLM with broad public access, and it onboarded users fast inside China.
ERNIE 4.0 (October 17, 2023) was the first version where Baidu’s claims started landing. CEO Robin Li announced it at Baidu World 2023, claiming parity with GPT-4. Independent testing showed ERNIE 4.0 was genuinely strong on Chinese language tasks and current affairs, and weaker than GPT-4 on coding and complex reasoning. Analyst reaction was mixed. The model picked up users quickly inside China, hitting roughly 45 million users in its first months and 70 million by late 2023, against ChatGPT’s 150 million at the time.
ERNIE 4.5 (June 30, 2025) was a turning point. Baidu open sourced the entire 4.5 family under Apache 2.0, releasing ten variants from a 0.3B dense model up to a 424B parameter MoE with 47B active. On CMMLU it set a new state of the art for Chinese language understanding, and on MMLU it matched GPT-4 class performance. Multimodal scores edged past GPT-4o on Baidu’s reported benchmarks (79.6 vs 79.14 on combined text). Reception in the open-source community was strong, and ERNIE 4.5 quickly became one of the more widely deployed open weight models inside China. The X1 reasoning variant, released alongside, was Baidu’s first serious entry into the deliberate-reasoning category, priced at roughly 1% of GPT-4.5.
ERNIE 5.0 (January 22, 2026) was the architectural leap. A 2.4 trillion parameter MoE with native multimodal handling for text, images, audio, and video, activating less than 3% of parameters per inference. ERNIE 5.0 became the first Chinese model to crack the LMArena global top 10, scoring 1460 and ranking #8 on the text leaderboard. It came in #2 globally on math, behind only GPT-5.2 (High), and the 5.0-Preview-1220 vision build hit #8 globally on the vision leaderboard, the only Chinese model in that top 10. Reception was strong on raw capability but mixed on production reliability, with several developers flagging tool-call loops and rough edges in agentic workflows. Baidu’s consumer-facing ERNIE Assistant crossed 200 million monthly active users around the same launch window.
ERNIE 5.1 (May 8, 2026) is the version we are covering here. It does not try to push parameter count higher. It pushes parameter efficiency instead, extracting an optimal sub network from 5.0 and continuing training on top.
The pattern across the line is consistent. ERNIE has historically been strongest on Chinese language tasks, search grounded queries, and structured reasoning, and historically weakest on coding, broad English world knowledge, and multi step agentic execution. ERNIE 5.1 closes some of those gaps but does not eliminate them.
Benchmark Results
Baidu published direct comparisons between ERNIE 5.1, DeepSeek V4 Pro, Claude Opus 4.6, and Gemini 3.1 Pro across agentic, knowledge, reasoning, and instruction following categories.
The headline numbers are:
- AIME26 (math reasoning with tools): 99.6, second only to Gemini 3.1 Pro
- τ³-bench (multi turn tool use): surpasses DeepSeek V4 Pro, trails Claude Opus 4.6
- SpreadsheetBench-Verified: surpasses DeepSeek V4 Pro, trails Claude Opus 4.6 and Gemini 3.1 Pro by a wide margin
- GPQA (graduate level science): second to Gemini 3.1 Pro, ahead of DeepSeek V4 Pro and Claude Opus 4.6
- MMLU-Pro (broad knowledge): ranks last of the four, with a visible gap to the leaders
- AdvanceIF (complex instruction following): second to Gemini 3.1 Pro, ahead of the rest
The pattern is consistent. ERNIE 5.1 is highly competitive on tool augmented math, structured reasoning, and instruction following, but loses ground on broad world knowledge tests, deep search agent tasks, and the harder spreadsheet automation scenarios.
In Baidu’s internal evaluations, ERNIE 5.1’s creative writing quality is described as approaching Gemini 3.1 Pro, which is currently considered the strongest writing model in the field.
Search Performance and the LMArena Result
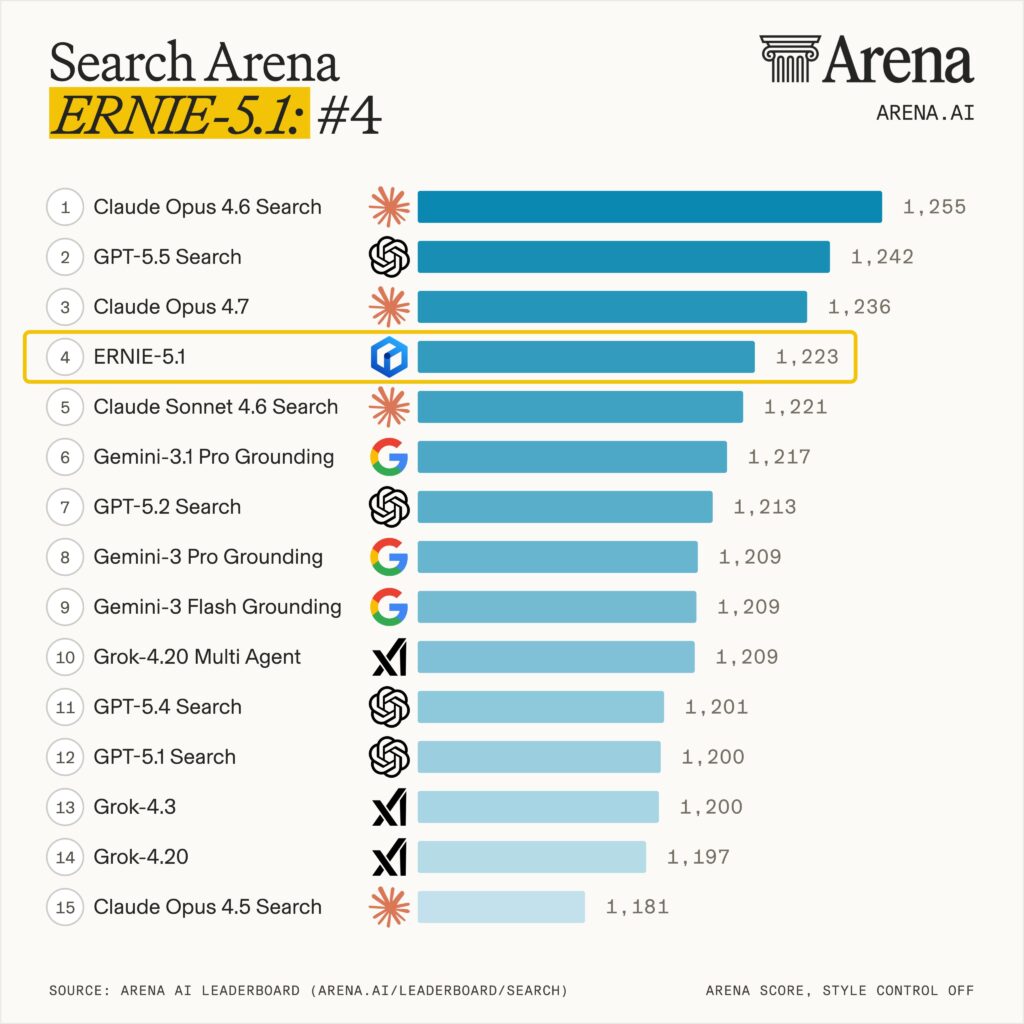
The most surprising result is on search. ERNIE 5.1 ranked #4 globally on the LMArena Search Arena leaderboard with a score of 1223, the only Chinese model in the global top 10. This places Baidu inside the top three labs worldwide for search performance, alongside the Western frontier players.
This is not an accidental result. Baidu has been the dominant search engine in China for two decades, and search grounding is built into the ERNIE deployment stack. ERNIE 5.1 inherits direct access to live search and structured retrieval, and Baidu has clearly optimized the model to use that retrieval well, including ranking, source synthesis, and citation behavior.
For Chinese users, this combination matters. A model that natively pulls from Chinese language sources and ranks them properly is a meaningful differentiator over models trained primarily on English web data.
Multi Dimensional Elastic Pre Training
The 6% pre-training cost claim rests on a technique Baidu calls Once-for-All elastic training, applied in multiple dimensions during the ERNIE 5.0 run.
In a normal training pipeline, you pick a target architecture (depth, width, sparsity, expert count) and train one model. If you want a smaller variant, you train it again from scratch or distill from the large one. This is expensive.
Baidu’s elastic approach trains a single super network that, through dynamic sampling during pre-training, simultaneously optimizes a wide matrix of sub networks across:
- Elastic depth: variable Transformer layer counts
- Elastic width: variable expert capacity inside the MoE
- Elastic sparsity: variable Top-k routing during forward passes
When pre-training finishes, you can pull any sub network out of the matrix and you get a usable model. ERNIE 5.1 is the strongest one in that matrix at its target parameter range.
Because the underlying compute was already spent on ERNIE 5.0, extending and refining ERNIE 5.1 requires only a fraction of the cost a fresh pre-training run would need, hence the 6% figure. Baidu has not specified the exact comparison model behind that number, and the figure should be read as a directional efficiency claim rather than a precisely audited benchmark.
The energy implication is real either way. Industry estimates put GPT-4 class training at around 240 million kWh of electricity. The equivalent ERNIE 5.1 training cost would land closer to 6 million kWh.
Decoupled Fully Asynchronous RL
ERNIE 5.1’s post-training was run on a new infrastructure that Baidu built specifically for long-horizon agentic reinforcement learning.
In a standard RL post-training stack, four components are tightly coupled: the trainer, the inference engine, the reward model, and the agent loop. When one slows down, everything stalls. For agentic RL, where rollouts can be long and tool use is involved, that coupling is a serious bottleneck.
Baidu fully decoupled these components. Trainer, rollout engine, reward computation, and agent loop now run independently with their own scaling profiles. If rollouts become the bottleneck, only that stage scales out, and control flow is separated from data flow so pipeline stages can overlap.
Two implementation details stand out:
- FP8 training and inference parity. The team unified low-precision operators across training and rollout, and combined this with optimized rollout router replay. The result is a 50% reduction in KL divergence between training and inference distributions, with effectively no added wall-clock time. For MoE models this matters because router drift between train and inference is a known stability issue.
- Heterogeneous CPU pooling. Idle CPU cores across the cluster are pooled and used for code sandboxes, verifiers, and other non GPU workloads. This is a small detail but it materially raises cluster utilization during long agentic rollouts.
The combined effect is faster iteration on agentic skills, which is reflected in ERNIE 5.1’s strong showing on τ³-bench and tool augmented math.
The Four Stage Post Training Pipeline
Most labs do post-training as a long sequential chain. ERNIE 5.1 splits the work into four distinct stages, with parallelism inside the heaviest steps.
- Unified SFT. A first pass of supervised fine-tuning on broad multi-domain instruction data. This locks in baseline instruction following and tool calling.
- Parallel domain expert training. Separate expert models are trained for code, reasoning, agentic behavior, and other domains. Each uses its own reward signal and algorithm, with no cross-domain interference. Capability collisions, where improving math hurts dialogue quality, are avoided at this stage.
- On-Policy Distillation (OPD). The unified SFT model becomes the student. It samples rollouts under its own policy, and uses token level KL alignment to absorb knowledge from each expert teacher in parallel. This is how Baidu fuses multiple specialists into a single deployable model.
- General online RL. For high-entropy tasks like open-ended chat, creative writing, and human preference alignment, distillation tends to flatten outputs. Those tasks are skipped in stage 3 and handled with a final round of online RL that preserves diversity.
The split is the important part. Deterministic capabilities (code, math, structured reasoning) are fused via distillation. Open-ended capabilities (writing, dialogue) are handled with RL. By keeping the two paths separate, ERNIE 5.1 avoids the common failure mode where math quality goes up while writing quality goes down.
Real World Capabilities
Independent hands-on testing from Chinese tech outlets gives a useful read on what the benchmarks translate into.
Creative writing. ERNIE 5.1 handles short story outlines, suspense fiction, and sci-fi micro fiction with solid structural quality. The thinking variant produces noticeably better results than the fast variant on emotional tone and narrative consistency. The fast variant occasionally scrambled character roles in longer pieces, which the thinking variant did not. Style is competent but plot construction can be formulaic for readers used to genre fiction.
Math reasoning. Given a 2025 Chinese national exam probability problem, the model produced fully correct step-by-step solutions, including cross-validation between two different methods. This is consistent with the AIME26 score.
Information synthesis. Asked an open question about how to choose between DeepSeek V4 Pro and Claude Opus 4.6 for a non technical user, the model autonomously broke the task into multiple dimensions, produced comparison tables, segmented recommendations by user type, and noted hidden caveats. This kind of unstructured synthesis is one of its strongest areas.
Spreadsheet operations. Given a sales performance dataset, the fast variant required several rounds of clarification before producing a clean unified table. The thinking variant nailed it on the first attempt. Functional, but the gap between the two variants is wider here than in other categories.
Coding. This is the weakest area. Asked to produce a single-file HTML 3D fighting game (around 700 lines of generated code), the model produced runnable code with rendering bugs and broken combat input. A simpler endless runner request (around 600 lines) produced code that did not run at all. Practical coding is clearly behind Claude Opus 4.6 and Gemini 3.1 Pro.
If you want to try ERNIE 5.1 alongside Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4, and Perplexity in one place, you can access them all in Fello AI on Mac, iPhone, and iPad. One subscription, every frontier model, no juggling separate apps or accounts.
Where ERNIE 5.1 Falls Short
The honest read on the benchmarks reveals three real gaps.
Broad world knowledge. MMLU-Pro is the clearest weakness, with a visible gap to the leaders. For users who lean on a model as a general knowledge oracle without retrieval, ERNIE 5.1 will feel thinner than the top closed-source competitors.
Deep search agent tasks. Despite the strong Search Arena ranking, ERNIE 5.1 trails on deep multi step search agent benchmarks where the model has to plan, browse, and synthesize across many sources autonomously. Single turn search is excellent. Multi-step research workflows still lag.
Practical coding. Generation can produce hundreds of lines of plausible but broken code. The model knows what code should look like, but its ability to maintain global state across long programs is well behind frontier coding models. For Claude Code style workflows, this is the most important gap to be aware of.
Spreadsheet automation at scale. SpreadsheetBench-Verified results are well behind Claude Opus 4.6 and Gemini 3.1 Pro. For office automation use cases where the bar is reliable end-to-end execution on real workbooks, the gap is large enough to matter.
How It Compares
| Capability | ERNIE 5.1 | DeepSeek V4 Pro | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Math with tools (AIME26) | 99.6, #2 | 3rd | 4th | #1 |
| Multi turn tool use (τ³) | 2nd | 4th | #1 | 3rd |
| Spreadsheets | 3rd | 4th | #1 | 2nd |
| Graduate science (GPQA) | 2nd | 4th | 3rd | #1 |
| Broad knowledge (MMLU-Pro) | 4th | 3rd | 2nd | #1 |
| Instruction following (AdvanceIF) | 2nd | 3rd | 4th | #1 |
| Search Arena | #4 globally | not ranked top | not ranked top | top tier |
| Practical coding | weak | strong | strongest | strong |
| Creative writing | near top | mid | strong | top |
| Open weights | ERNIE family open | open | closed | closed |
The shape of ERNIE 5.1’s profile is closer to Gemini 3.1 Pro than to any other model. Both excel at tool augmented reasoning, search, and instruction following. Gemini still leads on raw knowledge and coding, but ERNIE 5.1 is competitive at a fraction of the training spend.
Against DeepSeek V4 Pro, the comparison is more mixed. DeepSeek leads on practical coding and broader API maturity. ERNIE 5.1 leads on agentic tool use, search, and instruction following. For Chinese language tasks specifically, ERNIE 5.1 has a clear edge.
Against Claude Opus 4.6, Anthropic still leads on multi turn tool use, spreadsheets, and coding. ERNIE 5.1 closes ground on math, search, and instruction following. The Claude family remains the more reliable choice for production agentic workloads in English.
Availability and Pricing
ERNIE 5.1 is available right now through three channels:
- The consumer chat interface at yiyan.baidu.com (also reachable via ernie.baidu.com)
- The Baidu AI Studio Model Playground for developers
- API access through Baidu’s Qianfan platform
Both a fast variant and a thinking variant are available. The thinking variant is the better default for non trivial tasks, including writing, structured analysis, and any spreadsheet work. The fast variant is fine for quick lookups and simple chat.
Baidu has not published official API pricing for ERNIE 5.1 at launch. ERNIE 4.5 family models were priced aggressively against DeepSeek and the GPT-4 tier, and the same direction is expected here once pricing pages update.
ERNIE 5.1 is also being rolled out through more than 10 partner creative platforms inside the Baidu ecosystem, including ISEKAI ZERO, Mulan AI, and Storymaster.
Why This Release Matters
Three things stand out.
First, ERNIE 5.1 is the strongest signal yet that frontier-level performance does not require frontier-level compute. The 6% pre-training cost claim rests on a non-trivial architectural innovation (multi dimensional elastic training) and is backed by real benchmark results, not just marketing. If other labs adopt similar elastic pre-training methods, the cost curve for new model generations could bend significantly.
Second, the release further closes the gap between Chinese and Western labs at the top end. Six months ago, the strongest Chinese model on LMArena was sitting outside the global top 20. ERNIE 5.1 is now at #14 on the text leaderboard and #4 on Search. The Chinese frontier is no longer one or two model generations behind. It is contemporary.
Third, search is now a real capability dimension that frontier models compete on. ERNIE 5.1’s #4 Search Arena finish is not a side metric. As more workflows shift toward retrieval grounded answers, the labs that own a real search index, like Baidu and Google, have a structural advantage that pure language model labs do not.
For users who want to compare ERNIE 5.1 against the rest of the frontier without juggling multiple subscriptions, Fello AI gives you Claude 4.6, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4, Perplexity, and more in a single native app for Mac, iPhone, and iPad. One place to test prompts side by side, see which model handles your work best, and switch instantly.
ERNIE 5.1 is the second major Chinese frontier release of 2026, after DeepSeek V4. The next ERNIE generation is expected later this year, and based on the elastic pre-training approach, it is reasonable to expect future ERNIE versions to keep extracting value from the existing 5.0 super network rather than starting from scratch. That is a different competitive playbook from the rest of the field, and it is one worth watching.




