
In a breakthrough paper, Apple researchers reveal the uncomfortable truth about large reasoning models (LRMs): their internal “thought processes” might be nothing more than performative illusions. These are the very models that claim to think step-by-step like humans, thanks to techniques like chain-of-thought prompting, scratchpads, and tool-augmented reflection.
And yet, behind the scenes, something far less intelligent is happening. Apple’s study shows that these models often talk the talk—but fail to walk the walk when the complexity of reasoning tasks crosses a certain threshold.
The researchers built a suite of controlled, symbolic puzzles: Tower of Hanoi, River Crossing, Blocks World, and Checker Jumping. These aren’t just logic games—they’re diagnostics for how an AI handles planning, problem solving, and compositional reasoning. And for the first time, every intermediate step could be automatically checked.
The findings were alarming. At first, performance improves when models generate their own thought processes. But then, past a certain level of complexity, the very same models start collapsing. They use fewer tokens. They give up on reflection. They fail.
How Apple Designed a True Test of “Thinking”
Most AI benchmarks today reward right answers—but they don’t care how the model got there. That creates a loophole. A model can ace a test just by memorizing patterns or spitting out popular responses.
Apple closed that loophole. They focused not on final answers but on verifying reasoning step by step. In each symbolic puzzle, the model had to:
- Decompose the task
- Plan intermediate steps
- Apply rules accurately
- Generalize to novel inputs
These tasks weren’t cherry-picked. They were mathematically controllable, allowing Apple to scale the difficulty (e.g., by adding disks to Hanoi or increasing object counts in Blocks World).
To isolate the effect of “thinking,” each model was run in two modes:
- Silent LLM: Predict the answer directly, without a scratchpad.
- LRM: Predict using chain-of-thought reasoning visible in the output.
This let researchers see when thought traces help, when they hurt, and what really happens as complexity increases.
The Three Regimes of Reasoning Performance
After running thousands of experimental trials across a wide range of symbolic tasks, Apple’s researchers discovered a distinct, three-phase pattern in how large language models behave when faced with varying levels of complexity.
The performance of both standard language models (LLMs) and their reasoning-augmented counterparts (LRMs) changes dramatically depending on the cognitive difficulty of the task at hand.
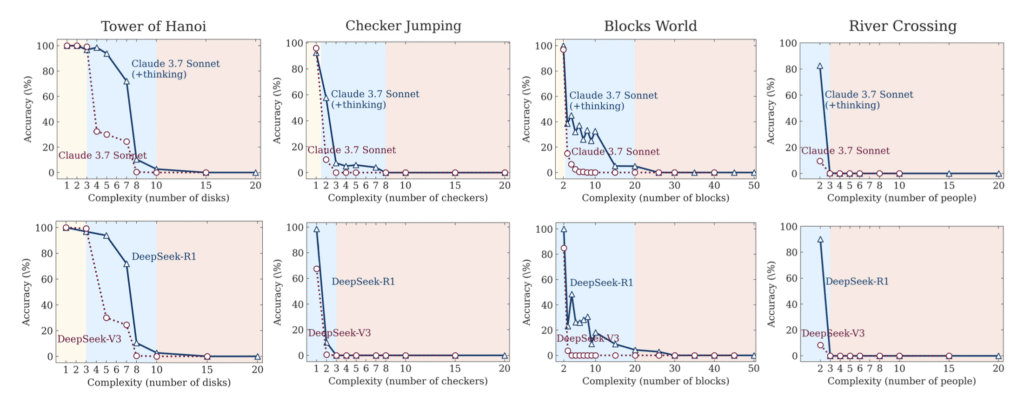
1. Low Complexity
When tasks are simple—such as solving the Tower of Hanoi with just a few disks—standard LLMs often outperform LRMs. This might seem counterintuitive, but there’s a reason: the additional step-by-step reasoning that LRMs produce doesn’t always add value. In fact, it frequently introduces unnecessary complexity.
The model might explain too much, loop over redundant thoughts, or even replace a good plan with a flawed one. In these scenarios, “thinking” too hard leads to degradation in output quality. It’s overthinking in its most literal form: the more the model talks, the more it trips over itself.
2. Medium Complexity
In moderately complex scenarios, LRMs start to prove their worth. The added thought trace enables the model to plan, verify, and revise its intermediate steps. This is the sweet spot where reflective reasoning pays off. Apple’s analysis shows clear cases in which an LRM initially takes a wrong path but course-corrects mid-process, ultimately arriving at the right solution.
These are the tasks that lie just beyond rote pattern recognition—where the ability to reason about structure, sequence, and causality provides a real advantage. In this middle regime, the “illusion of thought” briefly becomes a useful tool.
3. High Complexity
The real revelation comes when task complexity is ramped up to higher levels. Across all puzzle types—Hanoi, Blocks World, River Crossing—model performance collapses. Crucially, LRMs do not fail more gracefully than LLMs; they fail just as hard, and often earlier. Instead of writing longer reasoning chains to handle complexity, LRMs start producing shorter, shallower outputs. Token usage paradoxically decreases despite the task demanding more thought. It’s as if the model throws in the towel.
Even worse, providing external help doesn’t save them. When handed a perfectly valid algorithm as a tool, the models still falter. Execution breaks down, not due to misunderstanding the prompt, but because the model cannot maintain coherent stepwise logic as complexity exceeds its generalization capacity. In short, thinking harder doesn’t improve outcomes—it only prolongs the failure.
puzzle environments. [fuente]
What’s Actually Inside the “Thoughts”?
Apple didn’t just grade outputs—they analyzed the reasoning traces.
- In easy tasks, LRMs often arrive at a correct plan but sabotage themselves with extra, unnecessary steps.
- In moderate tasks, incorrect ideas dominate early reasoning, but successful paths sometimes emerge through self-correction.
- In hard tasks, LRMs never reach a valid plan. Their traces grow shallow and less coherent.
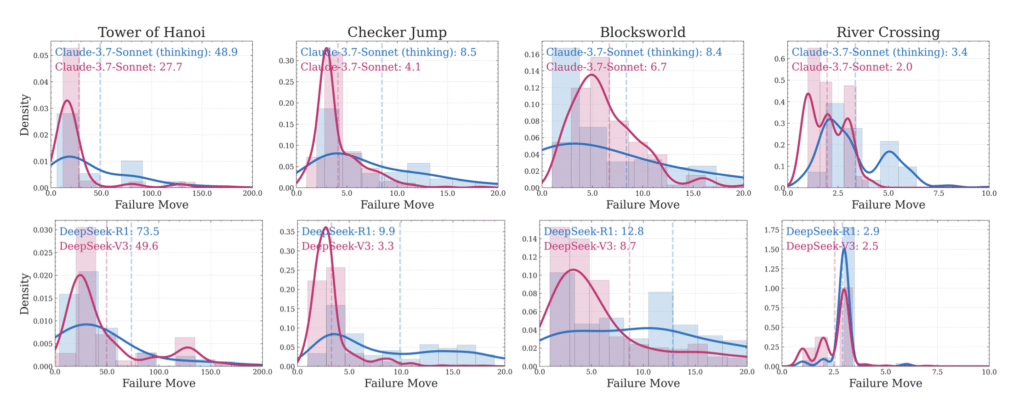
What’s shocking is how brittle this process is. One model might solve Hanoi (N=10) flawlessly for 100+ steps, but fail River Crossing (N=3) after just four moves.
Why Bigger Isn’t Smarter
In the world of AI, there’s a persistent belief that scaling—adding more tokens, training longer, using bigger models—can fix almost anything. But Apple’s findings directly challenge this assumption.
More Tokens, Same Results
While it’s true that larger context windows and more processing power allow models to “think” longer, this does not always translate to improved accuracy. In fact, as task complexity increases, Apple observed a surprising trend: models began using fewer tokens in their thought traces. It wasn’t a constraint issue—it was a breakdown in internal coherence. The models simply couldn’t sustain reasoning beyond a certain threshold, regardless of available compute.
Conceptual, Not Computational
This leads to a key takeaway: the failure is not due to a lack of resources—it’s rooted in the model’s architecture and training paradigm. The models are fundamentally limited in their ability to generalize logical procedures. They don’t know how to think; they just simulate what thinking looks like. As complexity grows, this illusion collapses.
No Shortcut Through Scale
Adding more GPUs or context isn’t the fix. Until foundational changes are made in how these models understand, verify, and correct their own reasoning steps, scaling will continue to yield diminishing—and often misleading—returns.
AI That “Thinks” Still Doesn’t Understand
So what do we make of this illusion of thought?
- LRMs aren’t general reasoners. They perform well only in a narrow band of complexity.
- Longer traces don’t mean smarter thinking. Sometimes, they mean confusion or token budget exhaustion.
- Access to tools or scratchpads doesn’t guarantee correctness. Execution fidelity remains unreliable.
Apple suggests this isn’t just a bug—it’s a structural limitation. LRMs are pattern matchers, not planners. Their seeming ability to reason is a shallow imitation of true understanding.
That’s not to say the future is bleak. These results might pave the way for hybrid models that combine LLMs with symbolic reasoning engines or self-verification loops.
But for now, Apple’s message is clear: beware the illusion. Today’s smartest models can still fail at puzzles your 10-year-old niece can solve.
Reflexiones finales
The hype cycle around AI often jumps ahead of reality. We love the idea of machines that can reason like us. But Apple’s work is a rare act of humility: showing that even the best models don’t truly “think.”
This paper is more than academic. It tells us where AI falls short, and where real progress is still needed:
- Better generalization across complexity gradients
- Execution mechanisms that verify, not just generate
- A shift from surface performance to structural competence
Until then, our AI might sound smart. It might even show its work. But deep down, it’s still just guessing.
And now, thanks to Apple, we know exactly when—and how—that guesswork falls apart.




