
Meta, the parent company of Facebook, Instagram, and WhatsApp, has officially unveiled Llama 4, the latest evolution in its line of large language models (LLMs). Designed to push the boundaries of what AI systems can understand and generate, Llama 4 introduces a powerful new foundation for building multimodal applications—those that work across text, images, and video—all in a single unified model. Released as open-weight models, Llama 4 is now available to developers and enterprises via platforms such as Azure AI Foundry, Azure Databricks, Hugging Face, and GroqCloud.
The Llama 4 family includes two production-ready models: Llama 4 Scout and Llama 4 Maverick, both offering high performance, efficient deployment, and broad compatibility with today’s most pressing AI workloads. A third model, Llama 4 Behemoth, is currently in training and is expected to become one of the largest and most intelligent open models ever released—boasting nearly two trillion parameters.
Meta has positioned Llama 4 as a cornerstone of the future AI ecosystem. By combining cost-effective deployment, massive input context windows, native multimodal understanding, and rigorous safety mechanisms, these models are designed to serve a wide range of use cases—from enterprise search to AI-powered creative assistants. With Llama 4, Meta is not just introducing a new model—it’s setting the stage for a new generation of intelligent, responsive, and safer AI applications..

Technical Innovations
Llama 4 stands out not only for its capabilities but also for the groundbreaking technical architecture that powers it. Meta has redesigned the model foundation from the ground up to support modern AI workloads.
Central to this effort are innovations in how the models manage compute efficiency, process multimodal inputs, and handle extremely long context lengths. Below, we explore the three core technologies behind Llama 4’s breakthrough performance: Mixture of Experts (MoE), early-fusion multimodalityet extended context through iRoPE.
Mixture of Experts (MoE) Architecture
Llama 4 is built using a sparse Mixture of Experts (MoE) architecture. This design includes many specialized neural networks (called “experts”) within a single model. During inference, only a small number of these experts are activated for each input. For example, Llama 4 Maverick has 128 experts and 400 billion total parameters, but only 17 billion active parameters are used per input.
This approach offers a major advantage: it increases performance while reducing compute costs. Scout, the smaller of the two public models, has 16 experts and 109 billion total parameters, also with 17 billion active parameters per token. These models use alternating dense and MoE layers, allowing for fast inference even at scale.
Native Multimodal Early Fusion
Unlike many older models that add image and video support as an afterthought, Llama 4 treats text, images, and video frames as a single stream of tokens right from the start—a method known as early fusion. This allows the model to understand and generate across multiple types of content in a unified way.
This makes Llama 4 ideal for real-world use cases like summarizing technical documents that include diagrams, answering questions about video transcripts and visuals, or generating media-rich reports.
Record-Breaking Context Window
Llama 4 Scout features an industry-leading 10 million token context window, enabling it to handle extremely large documents, multi-document summarization tasks, or detailed user histories in a single input. For comparison, most large models support context windows in the range of 32K to 128K tokens.
Scout achieves this through interleaved attention layers and a novel positional encoding method called iRoPE(interleaved Rotary Positional Embeddings), improving generalization across long contexts.
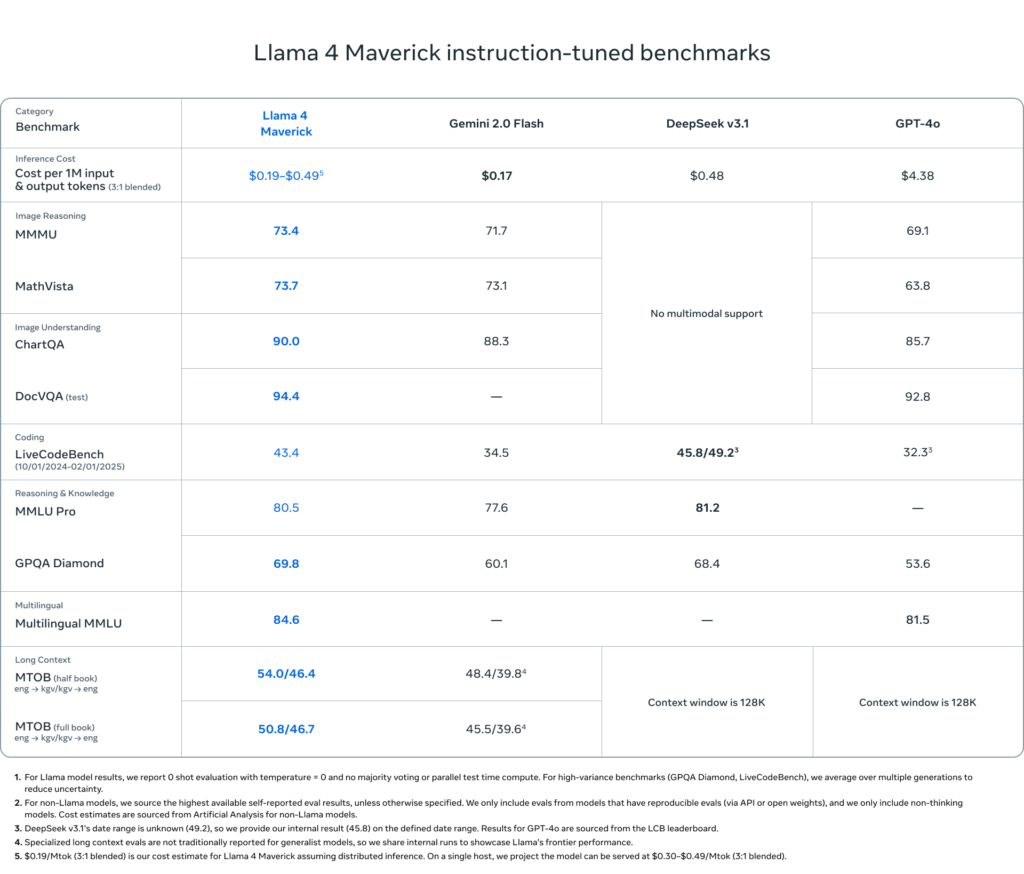
Performance in the Real World
Llama 4 models deliver strong results across common benchmarks. In internal testing, Maverick outperformed OpenAI’s GPT-4o and Google’s Gemini 2.0 Flash on several image, multilingual, and reasoning tasks. Meanwhile, Scout beats Gemini 2.0 Flash-Lite and Mistral 3.1 in long-context and code-heavy workloads.
Llama 4 Scout excels at use cases requiring large-scale input parsing, such as analyzing legal documents, summarizing technical manuals, or reasoning across large datasets. Maverick, on the other hand, is optimized for conversational AI, chatbots, creative writing, and image+text interactions, supporting 12 languages.
Performance benchmarks:
- Token throughput: Over 460 tokens/sec on GroqCloud
- Maverick ELO (chat assistant benchmark): 1417 on LMArena
- Supported languages: English, Spanish, French, German, Japanese, Korean, Chinese, Russian, Arabic, Portuguese, Hindi, and Indonesian
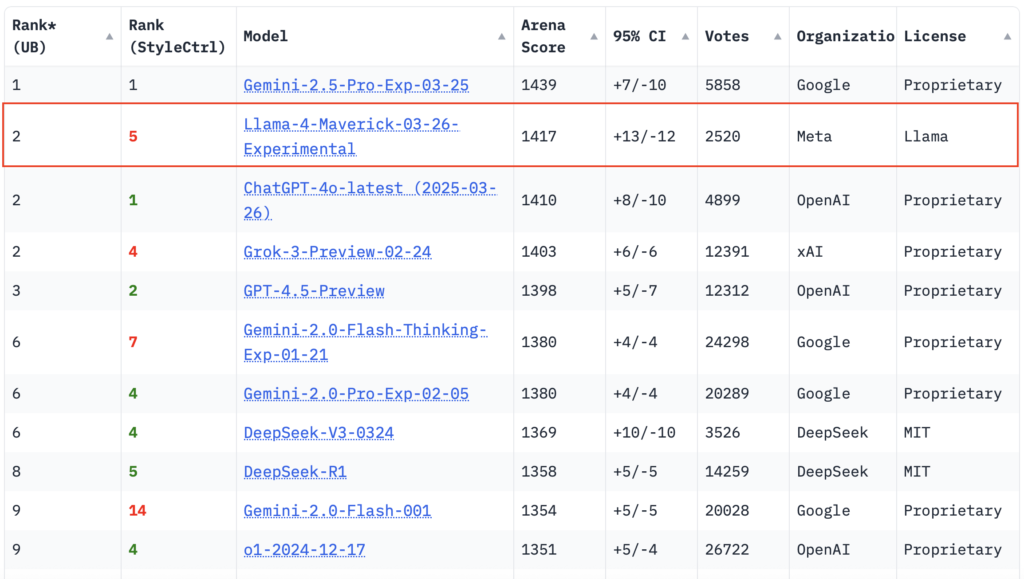
Safety, Bias Mitigation, and Trust Tools
Llama 4 introduces strong safeguards, built into both the training process and deployment options. Meta used a multi-stage post-training pipeline:
- Supervised Fine-Tuning (SFT) on hard datasets
- Online Reinforcement Learning (RL) with challenging prompts
- Direct Preference Optimization (DPO) for refining quality
Meta filtered out over 50% of “easy” training prompts, focusing only on medium-to-hard samples to push the models’ reasoning and robustness.
Meta also reduced model refusals to respond to contentious or political prompts from 7% (Llama 3.3) to under 2% (Llama 4). The models now offer more balanced and informative replies across debated topics.
Safety tools available for developers:
- Llama Guard: Detects harmful input/output
- Prompt Guard: Identifies adversarial prompts (like jailbreaks)
- CyberSecEval: Evaluates cybersecurity risks
Meta also introduced GOAT (Generative Offensive Agent Testing), an automated red-teaming framework that simulates adversarial interactions and helps identify weaknesses in model behavior.
Broad Ecosystem Availability
Llama 4 is deeply integrated with major cloud providers and developer platforms:
- Azure AI Foundry & Databricks: Managed compute offerings for scalable enterprise use
- GroqCloud: Low-latency and lowest-cost inference
- Hugging Face & llama.com: Open download access for research and self-hosting
Meta AI built on Llama 4 is also available directly in popular products such as WhatsApp, Messenger, Instagram Direct, and the Meta.AI website.
Meta’s open-weight approach encourages experimentation and wide adoption, lowering the barrier for developers, researchers, and startups to build on top of high-quality AI systems.
Llama 4 Behemoth Coming Soon
Llama 4 Behemoth is still in training but is expected to be among the most powerful AI models yet released:
- 288B active parameters, 2 trillion total parameters
- 16 experts, used as a “teacher” model for distilling Scout and Maverick
- Outperforms GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Pro on STEM, mathet code benchmarks
Behemoth uses codistillation to train smaller models more efficiently. Its training process included:
- Lightweight SFT and advanced online RL
- Prompt filtering based on difficulty levels
- Parallelized training infrastructure with dynamic expert allocation
The model is being optimized to retain strong reasoning, long-context handling, and STEM performance while maintaining fast response times. Though not publicly released, Behemoth lays the groundwork for future high-performance Llama models.
Conclusion
Llama 4 represents a major leap forward in open-source AI. With Scout and Maverick now available—and the massive Behemoth model on the horizon—Meta is delivering one of the most advanced, efficient, and accessible model families to date. These models combine cutting-edge architecture, native multimodal support, and record-breaking context windows with a strong emphasis on safety and responsible deployment.
From summarizing lengthy documents to powering enterprise-grade chatbots, Llama 4 models are built for real-world impact. Meta’s open-weight release strategy—alongside integration with platforms like Azure, Hugging Face, and GroqCloud—makes these tools broadly usable and cost-effective across industries.
More than just a technical achievement, Llama 4 signals a shift toward scalable, safe, and community-accessible AI. It lays the groundwork for a new era of intelligent, human-aligned applications—and opens the door for developers everywhere to build what comes next.




