
On May 5, 2026, a Miami-based startup called Subquadratic came out of stealth with $29 million in seed funding and a single, very loud claim: it has built the first frontier LLM that does not rely on quadratic attention. Its model, SubQ, ships with a 12 million token context window, runs roughly 52x faster than FlashAttention at 1 million tokens, and costs about a fifth of what Claude Opus or GPT-5.5 charge for comparable workloads.
If those numbers hold up, this is the most significant architectural shift in language models since the original 2017 transformer paper. If they do not, it joins a long list of subquadratic experiments that promised the world and quietly underperformed at scale.
This review walks through what SubQ actually is, how its Subquadratic Sparse Attention (SSA) mechanism works, what the benchmarks show, what credible researchers are skeptical about, and how to think about it if you build with AI today.
Key Takeaways
- Launched May 5, 2026 by Subquadratic, founded by CEO Justin Dangel and CTO Alex Whedon (former Head of Generative AI at Meta).
- $29M seed round with backers including Justin Mateen (Tinder co-founder), Javier Villamizar (ex-SoftBank Vision Fund), and early investors in Anthropic, OpenAI, Stripe, and Brex.
- 12 million token context window in the research model, 1 million tokens in the production API.
- SSA architecture scales linearly with context length instead of quadratically, cutting attention compute by roughly 1,000x at 12M tokens.
- Benchmarks: 95.0% on RULER 128K, 65.9% on MRCR v2 at 1M tokens, 81.8% on SWE-Bench Verified.
- Three products in private beta: SubQ API, SubQ Code (CLI agent), and SubQ Search (free long-context research tool).
- Skepticism is high. The full technical report has not been released, weights are not open, and prior subquadratic architectures (Mamba, RWKV, DeepSeek Sparse Attention) have repeatedly underperformed transformers at frontier scale.
What SubQ Actually Is
SubQ is a closed-weights large language model trained on a brand new attention mechanism the company calls Subquadratic Sparse Attention, or SSA. Standard transformer attention compares every token in a sequence with every other token. That is what makes it powerful, and it is also what makes context windows expensive. Doubling the input quadruples the compute.
SSA replaces this with content-dependent token selection. For each query token, the model picks a small subset of positions in the sequence that actually matter, then computes exact attention only over those. Compute scales linearly with context length rather than with its square.
This is not the same as the fixed-pattern sparse attention used in Longformer or BigBird, where the sparsity is hardcoded by position. It is also not the state-space approach taken by Mamba or RWKV, which replace attention entirely with recurrent dynamics. SSA keeps attention, but makes it choose where to look.
Subquadratic claims this gives the model three properties at once: linear cost, content-aware routing, and the ability to retrieve from arbitrary positions in the sequence. Until now, sparse attention designs have generally hit two of those three.
How SSA Works
The company published a technical post breaking down the mechanism and the training pipeline. The short version:
- Pre-training establishes base language modeling and long-context representations across very long sequences.
- Supervised fine-tuning layers in instruction-following and code generation behavior.
- Reinforcement learning specifically targets long-context retrieval failure modes, the kind where the model produces a plausible-looking answer that quietly drops the wrong fact from a 200-page input.
The infrastructure piece matters as much as the math. Linear memory scaling and distributed sequence parallelism let Subquadratic train stably on sequences of one million tokens or more, something most labs avoid because the GPU memory cost is brutal under standard attention.
Hardware-wise, the wall-clock speedups they report are measured on Nvidia B200s using FlashAttention-2 as the baseline:
| Context length | SSA speedup vs FlashAttention-2 |
|---|---|
| 128K tokens | 7.2x |
| 256K tokens | 13.2x |
| 512K tokens | 23.0x |
| 1M tokens | 52.2x |
The further out you go, the bigger the gap. At 12 million tokens, Subquadratic claims attention compute drops by almost 1,000x versus standard transformers, which is the headline number being repeated everywhere.
The Benchmark Numbers
Subquadratic released three benchmark results alongside the launch. None are state-of-the-art across the board, but each one tells a slightly different story.
| Benchmark | SubQ | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.5 |
|---|---|---|---|---|
| RULER @ 128K (long-context retrieval) | 95.0% | 94.8% | n/a | n/a |
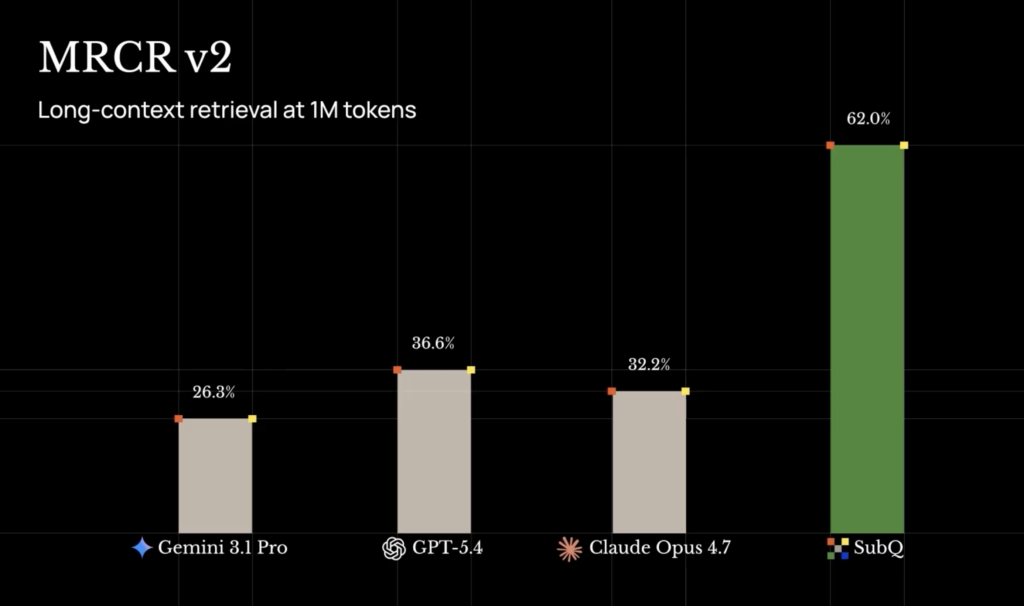
| MRCR v2 @ 1M (8-needle multi-round retrieval) | 65.9% | 32.2% (press) / 78.3% (technical post) | 26.3% | 74.0% |
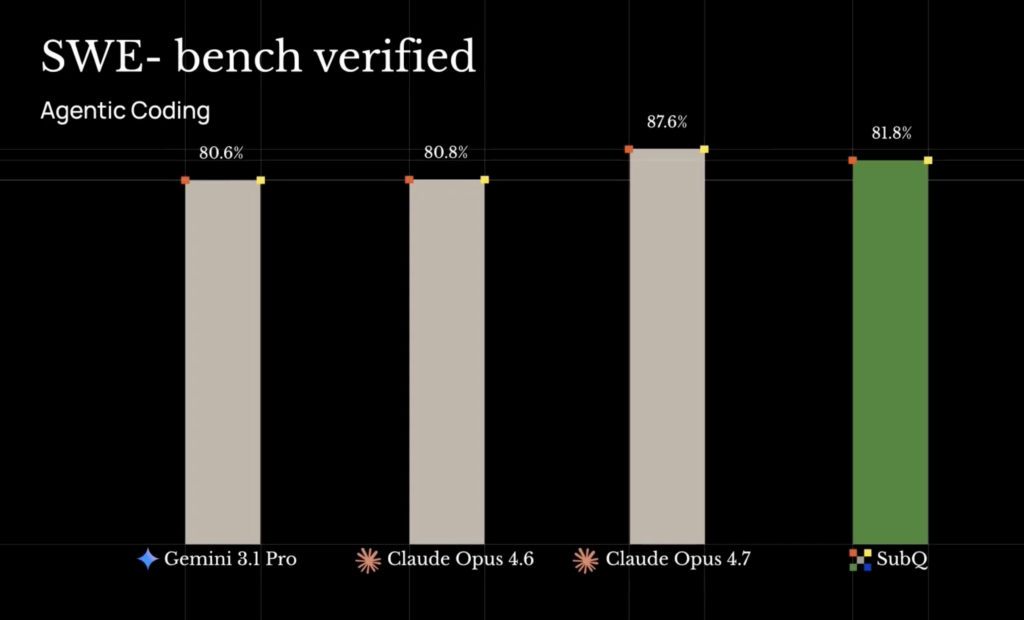
| SWE-Bench Verified (code) | 81.8% | 80.8% (press) / 87.6% (technical post) | 80.6% | n/a |
Two things stand out. First, RULER at 128K is essentially saturated, so SubQ matching Opus is more about not regressing than winning. Second, the MRCR and SWE-Bench numbers Subquadratic uses for Opus differ between its press release and its own technical post, which is strange and worth flagging. Either way, SubQ trails Opus on MRCR if you believe the technical post numbers, and beats it if you believe the press numbers.
What is not in dispute is the cost-per-result. On RULER 128K, Subquadratic says SubQ hits 95.0% accuracy at $8 of compute, against roughly $2,600 for Opus to hit 94.8%. That is a 300x cost reduction at the same accuracy, which is the part of the story that matters most for anyone shipping production AI workloads. Our AI pricing comparison covers what that kind of unit-economics shift looks like in practice across the major providers.
What 12 Million Tokens Actually Buys You
A 12M token window is roughly 9 million words, or about 120 books worth of text in one prompt. That is enough to fit:
- An entire mid-sized company codebase, including tests and documentation.
- Every legal filing in a complex case.
- A full year of customer support transcripts for a mid-market SaaS product.
- The entirety of the King James Bible roughly nine times over.
The practical implication, if SubQ delivers, is that retrieval-augmented generation (RAG) becomes optional for a much wider set of problems. Today, almost every serious AI deployment runs a retrieval pipeline because you cannot fit the relevant data into the context. Embed, chunk, rerank, stuff, generate. SubQ’s pitch is that for many of those workloads you can skip that whole stack and just put the documents in.
That does not eliminate RAG, but it does compress the use case. Static knowledge bases, internal codebases, and document review look like the obvious early targets. Real-time data, fast-changing information, and user-specific personalization still need retrieval.
The Three Products
Subquadratic launched three products simultaneously, all in private beta as of May 5.
SubQ API is the developer entry point. It exposes the 1M-token production model through OpenAI-compatible endpoints with tool use support. The 12M context window is gated to research and select enterprise partners for now.
SubQ Code is a CLI coding agent that loads entire codebases into context and reasons across them. Subquadratic also positions it as a long-context layer for existing tools, claiming compatibility with Claude Code, Codex, and Cursor. For what Cursor itself costs, see our Cursor pricing guide. Their published numbers claim a 25% lower bill and 10x faster exploration when SubQ Code sits underneath those agents. That is the most directly testable claim in the launch and the one most likely to either prove SubQ out or expose it.
SubQ Search is a long-context research tool offered free to consumers. Subquadratic is using it as a land-and-expand wedge against Perplexity and ChatGPT search. The economics presumably work because attention cost at 1M+ tokens is cheap on their stack and brutally expensive on everyone else’s.
Pricing for the API has not been disclosed yet beyond the general claim of being roughly one-fifth the cost of leading frontier models.
Why Researchers Are Skeptical
Within hours of the launch, the AI research community split. The case against SubQ is not personal. It is historical.
Subquadratic attention is one of the most heavily explored areas in machine learning. Mamba, RWKV, Hyena, RetNet, BASED, DeepSeek Sparse Attention, and Kimi Linear all took different swings at the same problem. Each one demonstrated linear scaling on benchmarks. Each one ran into the same wall: pure subquadratic architectures match dense attention at small and medium scale, then visibly underperform on downstream benchmarks at frontier scale, or end up in hybrid configurations that lose the pure scaling benefit.
A widely shared LessWrong post on this lineage argued that nearly all subquadratic claims to date are “incremental improvement number 93595 to the transformer architecture” because practical implementations remain quadratic in the regimes that matter and only improve attention by a constant factor.
Two specific concerns surfaced fast.
AI engineer Will Depue posted that SubQ is “almost surely a sparse attention finetune of Kimi or DeepSeek,” meaning the impressive base model behavior comes from existing open-source weights and the SSA contribution is the sparse attention layer added on top. Subquadratic has not denied or confirmed this, and has not released weights or a full technical report.
AI commentator Dan McAteer captured the binary mood: “SubQ is either the biggest breakthrough since the Transformer or it’s AI Theranos.” That is not a serious technical critique, but it is the right frame for how the field is reading this. Either the model is what Subquadratic says it is, or the gap between marketing benchmarks and production behavior will become visible quickly once outsiders get hands-on.
The clearest path to credibility is the technical report, the weights or detailed architecture description, and independent benchmarks from labs the company does not pay. Subquadratic says all three are coming. They are not here yet.
How SubQ Compares to Other Long-Context Models
Long-context is not a new battlefield. Gemini has shipped 2M token windows for over a year. Claude pushed past 1M last fall. The interesting comparison is on cost-at-context, not raw context length.
| Model | Max context | Cost per 1M output tokens (est.) | Architecture |
|---|---|---|---|
| SubQ (production) | 1M tokens | ~1/5 frontier rate | Subquadratic Sparse Attention |
| SubQ (research) | 12M tokens | claimed ~1,000x cheaper at 12M | Subquadratic Sparse Attention |
| Claude Opus 4.6 | 1M tokens | $75 | Dense transformer |
| Gemini 3.1 Pro | 2M tokens | $30 | Hybrid attention |
| GPT-5.5 | 400K tokens | $60 | Dense transformer |
| DeepSeek V3.2 | 128K tokens | $1.10 | Dense transformer with sparse layers |
The point of comparison is not whether SubQ wins on accuracy. On most benchmarks Opus or Gemini still leads. The point is whether the cost-per-correct-answer at long context is genuinely 50x to 300x lower, because if it is, the choice for any document-heavy or code-heavy workload changes.
What This Means for Builders
For most people shipping product on top of LLMs, here is the practical read.
If SubQ’s claims hold up under independent testing, three things change. RAG becomes optional for many use cases. Codebase-scale coding agents become economically viable. And the model selection layer that products like Fello AI bundle gets one more strong option, since the value of having a single Mac and iPhone interface to every frontier model only grows when the models start specializing on different axes (cost, speed, context, raw reasoning).
If SubQ’s claims do not hold up, the most likely outcome is that the SSA mechanism still ends up being a useful component in hybrid architectures, similar to how mixture-of-experts went from skepticism to standard practice over a few years. The 1,000x number gets walked back, the 50x number probably survives in narrower domains.
The most concrete thing to do today is wait for the technical report, run your own evaluations through SubQ Code on a real codebase you understand well, and treat the marketing benchmarks as a starting point rather than a verdict.
Pricing and How to Access SubQ
All three products are in private beta. Subquadratic is taking access requests through forms on its website. The company has not published a public pricing page yet. Based on launch interviews, expect:
- SubQ API: roughly 1/5 the per-token cost of Claude Opus or GPT-5.5 at comparable context lengths.
- SubQ Code: licensed per developer seat, with the long-context layer pitched as a drop-in cost reducer for teams already using Claude Code, Codex, or Cursor.
- SubQ Search: free to consumers during beta.
If you want to use SubQ alongside other frontier models without juggling separate accounts, an aggregator like Fello AI can sit in front of multiple providers on Mac, iPhone, and iPad. SubQ is not currently available in Fello AI because it is in private beta, but it will be added as soon as it releases publicly, or sooner if early access opens up.
Final Verdict
SubQ is the most architecturally interesting LLM launch since DeepSeek V3, and that is true whether or not the 1,000x number survives contact with independent reviewers. A linear-scaling attention mechanism that holds up on RULER, MRCR, and SWE-Bench is genuinely new, and the team behind it (ex-Meta, Google, Oxford, ByteDance, Cambridge research) is credible enough to take seriously.
The honest read is that the marketing is ahead of the evidence. The gap will close in one of two directions over the next quarter. Either the technical report, the weights, and the independent benchmarks confirm the headline numbers, in which case SubQ permanently changes how long-context AI is built, or the gap becomes the story and SubQ joins the long list of architectures that worked beautifully in a paper and disappointingly in production.
For now, SubQ earns a careful watch, an early-access request if you run long-context workloads, and a healthy dose of “wait for the technical report” before you bet anything serious on it.
FAQ
What is SubQ?
SubQ is a large language model launched May 5, 2026 by Subquadratic, a Miami-based AI startup. It uses a new attention mechanism called Subquadratic Sparse Attention (SSA) and supports a 12 million token context window in its research configuration.
What is Subquadratic Sparse Attention?
SSA is an attention mechanism that scales linearly with context length instead of quadratically. For each query token, the model selects a small subset of positions to attend to based on content rather than fixed patterns, then computes exact attention only over those.
How big is SubQ’s context window?
The research model supports 12 million tokens, roughly 9 million words. The production API exposes a 1 million token context window.
Is SubQ open source?
No. SubQ is closed-weights and not open source. Subquadratic has said a technical report is forthcoming but has not committed to releasing weights.
How does SubQ compare to Claude or GPT?
On long-context benchmarks like RULER 128K, SubQ is competitive with Claude Opus 4.6. On MRCR v2 at 1M tokens, it scores 65.9%, behind GPT-5.5’s 74.0%. The differentiator is cost: Subquadratic claims roughly 300x lower cost at the same accuracy on RULER 128K and 50x lower cost than frontier models at 1M tokens.
Can I use SubQ today?
Access is private beta only. The SubQ API, SubQ Code (CLI agent), and SubQ Search (free research tool) all require an access request through subq.ai. SubQ Search is the easiest entry point.
Is SubQ legit, or hype?
It is too early to say with confidence. The company has published benchmark results and a technical post explaining SSA, but has not released weights, a full technical report, or independent benchmarks. Several researchers, including Will Depue, have publicly questioned whether SubQ is a sparse-attention finetune of an existing open-source model rather than a fully new architecture. Independent verification over the next few weeks will decide it.




