
On June 1, 2026, MiniMax officially released M3, the Shanghai lab’s next flagship language model, and it shipped exactly as promised. The model that spent weeks as an architecture teaser is now live, and the pitch turned out to be real: frontier-level coding, a 1-million-token context window, and native multimodality, all in one open-weight model. MiniMax calls it the first and only open-weight model to bring all three together.
Open weights sit at the heart of open source AI, the category of models you can download and run yourself instead of renting access through a closed API.
The architecture story we covered before launch held up. M3 is built on the new MiniMax Sparse Attention (MSA) design, the same sparse attention the company had killed in its M2 generation and brought back for M3. You can use it right now through MiniMax Code, token plans, and the API, with open weights and a full technical report promised within roughly ten days. Below is what is confirmed at launch, what the benchmarks say, what it costs, and how much of it you should trust today.
Key takeaways
- Released and available now. M3 launched June 1, 2026, accessible through MiniMax Code, token plan subscriptions, and the standard API. Open weights and a technical report are due within about ten days on Hugging Face and GitHub.
- Three frontier capabilities in one model. MiniMax positions M3 as the first open-weight model to combine frontier coding, a 1M-token context window, and native image and video understanding.
- Sparse attention delivered. The MSA architecture cuts per-token compute at 1M context to one-twentieth of the prior generation, with more than 9× faster prefill and more than 15× faster decoding.
- Strong benchmarks, with caveats. M3 scores 59.0% on SWE-Bench Pro, beating GPT-5.5 and Gemini 3.1 Pro and approaching Claude Opus 4.7. Several results were run on MiniMax’s own infrastructure with agent scaffolding, so independent verification is still pending.
- Aggressively cheap. Input pricing starts at around $0.30 per million tokens, with a blended cost as low as $0.06 per million with cache optimization.
Where to use MiniMax M3 right now
M3 is available the moment it launched through three channels. You can call it via the standard API, subscribe to a MiniMax token plan, or use it inside MiniMax Code, the company’s agent product. The open weights and technical report are not out on day one; MiniMax says it will publish both on Hugging Face and GitHub over the next ten days or so.
That timing matters. Developers can test the hosted model immediately, but the open-weight claim is not fully proven until the weights and report are actually public. When they land, the repo to watch is huggingface.co/MiniMaxAI for a model card titled MiniMax-M3.
Inside MiniMax Sparse Attention (MSA)
The headline change is architectural, and it is the same one MiniMax teased before launch. M3 returns to sparse attention after the company spent the entire M2 generation, including M2, M2.1, M2.5, and M2.7, on full attention across the context window.
In plain English, full attention means every token in the context can look at every other token. That is accurate but expensive, and the cost explodes as the context grows. Sparse attention lets the model skip most of those connections and focus only on the tokens that matter. M3’s design uses a lightweight index branch to scan incoming tokens and pick which blocks of past tokens deserve attention, then runs attention only on those relevant key-value blocks.
The base is Grouped Query Attention (GQA), not Multi-head Latent Attention, with block-level selection performed on the real, uncompressed key-values rather than a compressed representation. That is the key detail. M3 keeps the precision of real attention computation while only doing it where it counts, which is how MiniMax claims to get the efficiency gains without sacrificing quality.
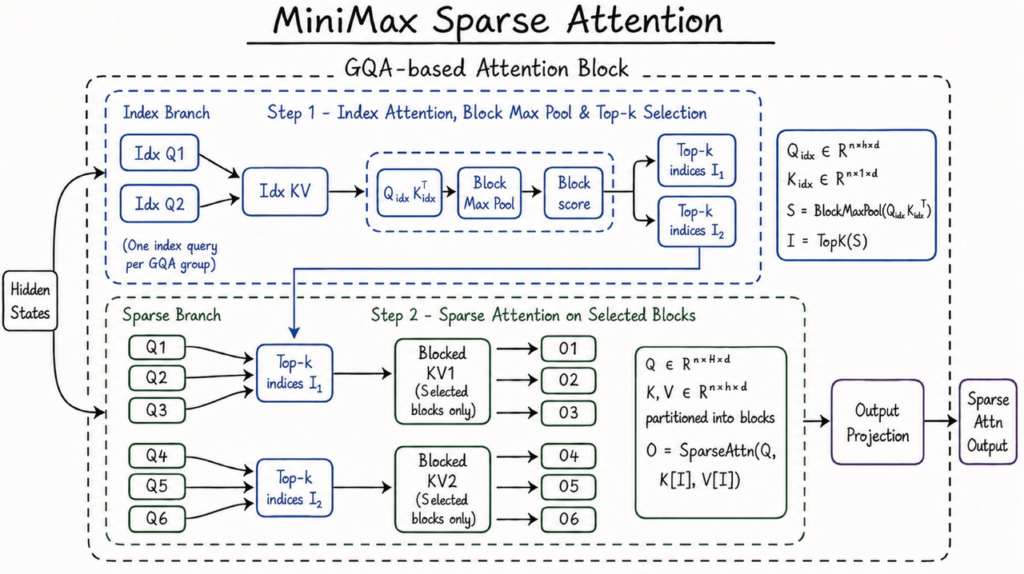
Why MiniMax killed sparse attention in M2 and brought it back
This is the part that makes the launch interesting, because it is a public self-correction. In MiniMax’s own engineering blog explaining the M2 architecture, the team wrote that “the infrastructure for linear and sparse attention is much less mature” than full attention, and that “efficient attention still has some way to go before it can definitively beat full attention.”
That was published roughly a year ago. With M3, the same team has shipped production-ready sparse attention with order-of-magnitude speedups. The bet is that the infrastructure caught up, and MSA is the proof they are putting in front of developers.
How fast is MiniMax M3?
The efficiency numbers are the clearest part of the release. All figures are measured at 1-million-token context length against the prior generation.
| Metric | MiniMax M3 |
|---|---|
| Per-token compute at 1M context | 1/20 of prior generation |
| Prefill (processing the input) | More than 9× faster |
| Decoding (generating output) | More than 15× faster |
| Output speed | ~100 tokens/sec, ~3× faster than Opus |
| Context window | Up to 1M tokens (guaranteed minimum 512K) |
This is the real business angle. Long context sounds impressive, but most teams do not need to dump a whole repository and a year of tickets into a single prompt. What they need is a model that keeps enough state to work over time without making latency and inference cost painful. By cutting per-token compute at 1M context to a twentieth, MSA is built to make long-context agents economical for ordinary developer workflows, not just demos.
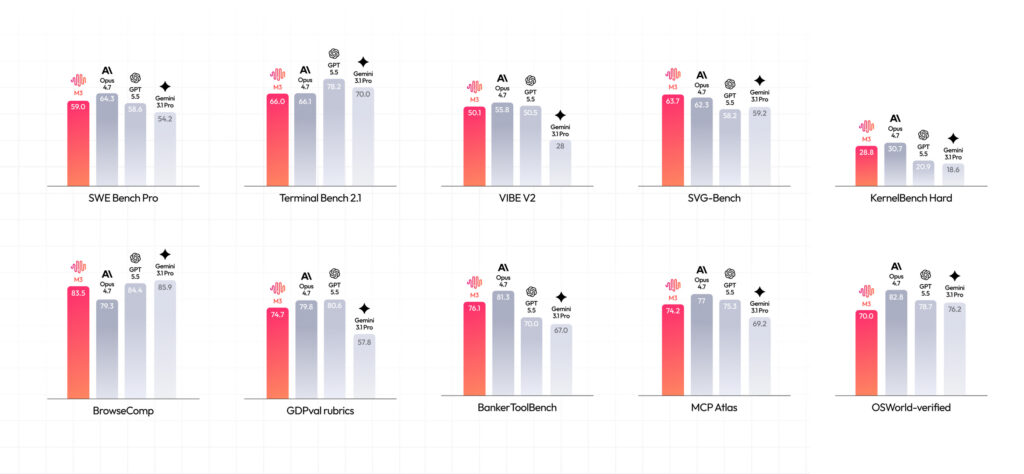
MiniMax M3 benchmark results
This is the data the pre-launch article could not show, because no accuracy benchmarks existed yet. Now they do. On coding and agentic tasks, M3 posts numbers that put it in frontier company.
| Benchmark | MiniMax M3 | What it measures |
|---|---|---|
| SWE-Bench Pro | 59.0% | Real-world software fixes |
| Terminal-Bench 2.1 | 66.0% | Command-line agent tasks |
| SWE-fficiency | 34.8% | Efficient code changes |
| KernelBench Hard | 28.8% | Low-level kernel optimization |
| MCP Atlas | 74.2% | Tool-use via MCP |
| BrowseComp | 83.5 | Web search and browsing |
The standout claims: on SWE-Bench Pro, M3 beats GPT-5.5 and Gemini 3.1 Pro and approaches Claude Opus 4.7. On BrowseComp, its 83.5 surpasses Opus 4.7’s 79.3. On the multimodal side, M3 scores above Gemini 3.1 Pro on OmniDocBench, takes the top spot on Claw-Eval (an end-to-end autonomous agent benchmark), and beats Opus 4.7 on SVG-Bench.
Treat these with the right amount of caution. MiniMax discloses that several results were run on its own infrastructure, often using agent scaffolding such as Claude Code, Mini-SWE-Agent, or Terminus. That does not make the numbers useless, but it does mean a model that looks strong on a leaderboard can behave differently inside a messy internal repository. M3 is also not yet on the DeepSWE board, where long-horizon software tasks are tracked, so a clean comparison against the very newest Claude releases still has to wait. Buyers should hold for independent runs before making procurement decisions.
How much does MiniMax M3 cost?
Pricing is where M3 makes its loudest argument, and our full MiniMax pricing guide maps it against every other plan. The API charges around $0.30 per million input tokens, and with cache optimization the blended cost drops to roughly $0.06 per million. A standard rate applies to requests up to 512K input tokens, with a higher rate above that for long-context scenarios, and both standard and priority service tiers are available.
For heavier users, MiniMax sells monthly token plans that work out cheaper per token.
| Plan | Price / month | Token allowance |
|---|---|---|
| Plus | $20 | ~1.7B tokens |
| Max | $50 | ~5.1B tokens |
| Ultra | $120 | ~9.8B tokens |
For comparison, Claude Opus 4.7 runs about $5 per million input tokens and $25 per million output. If M3 holds up on quality, it is more than 15× cheaper on input and open-weight on top of that.
What MiniMax M3 can actually do
MiniMax backed the launch with three long-horizon task demonstrations meant to show M3 working over many hours, not just answering prompts.
- Paper reproduction. M3 autonomously reproduced an ICLR 2025 paper in 12 hours, producing 18 commits and 23 figures.
- CUDA kernel optimization. Over a 24-hour run, M3 pushed FP8 hardware utilization from 7.6% to 71.3%, a 9.4× speedup, across 147 benchmark submissions.
- Autonomous model training. M3 scored 0.37 on PostTrainBench, a task that asks the model to train another model end to end.
These tie into MiniMax Code, the agent product wrapped around the model. It breaks complex work into multi-stage workflows using an Agent Team framework, runs a producer and verifier adversarial loop to catch its own mistakes, and supports computer use through M3’s native multimodal capabilities. Built partly on the OpenCode and Pi open-source projects, it puts MiniMax in the same lane as Anthropic’s Claude Code, OpenAI’s coding agents, and Google’s Gemini tooling. The product is no longer just the model, it is the model plus the harness around it.
MiniMax M3 vs M2.7 vs M2.5
Here is how M3 sits against MiniMax’s recent M-series and a major Western reference point, now that the M3 column can be filled with real data.
| MiniMax M3 | MiniMax M2.7 | MiniMax M2.5 | Claude Opus 4.7 (reference) | |
|---|---|---|---|---|
| Status | Released Jun 1, 2026 | Released Mar 18, 2026 | Released Feb 12, 2026 | Released |
| Attention | Sparse (MSA) | Full | Full | Proprietary |
| Context window | 1M tokens | Shorter, slow at 1M | Shorter | Long |
| Multimodal | Native (image + video) | Text-focused | Text-focused | Yes |
| SWE-Bench Pro | 59.0% | Competitive | Lower | Higher |
| Open weight | Yes (weights in ~10 days) | Yes, non-commercial | Yes | いいえ |
| Input pricing | ~$0.30 / M tokens | ~$0.30 / M tokens | Comparable | $5 / M tokens |
M2.7 remains the model most current MiniMax users are running, and it is not being deprecated. The difference is that M3 finally makes the 1M-token context practical instead of painfully slow, and adds native multimodality M2.7 never had. For background on how the M-series got here, see our MiniMax M2.5 breakdown. M3 is one of several June launches; days later Microsoft unveiled its own MAI models at Build.
How does MiniMax M3 compare to Claude, GPT-5.5, Gemini, and DeepSeek?
With benchmarks now public, the comparison is sharper than it was at the teaser stage, though independent verification is still the missing piece.
Against Claude Opus 4.7. Claude likely still edges M3 on raw reasoning quality, and it leads on the newest long-horizon coding tests. But M3 is open-weight, more than 15× cheaper on input, and it actually surpasses Opus 4.7 on BrowseComp web search. The gap that mattered for years has narrowed to a thin margin on specific tasks.
Against GPT-5.5 and Gemini 3.1 Pro. M3’s own numbers put it ahead of both on SWE-Bench Pro. The harder claim is the architecture: M3 says it made cheap 1M-token inference work in production, something the closed labs have not publicly committed to in the same terms.
Against DeepSeek V4 and Qwen3.7-Max. This is the closest fight. DeepSeek V4 and Qwen3.7-Max are M3’s real competitive set, all Chinese, all open-weight, all chasing the same agentic use cases. A fresh entrant to that same open-weight pack is Nex-N2-Pro, a 397B MoE model built for agentic coding. M3’s differentiator in this lane is the combination: it is the one bringing frontier coding, 1M context, and multimodality together at once.
For a broader read on how the U.S. and China model race is shaping pricing and licensing, see our Anthropic vs OpenAI breakdown.
Is MiniMax M3 open source?
It is open-weight, with the weights and a technical report due on Hugging Face and GitHub within about ten days of launch. Whether it counts as fully open-source depends on the license, which had not been published at launch.
The distinction matters. Open-weight means you can download the model files and run them locally. Open-source, strictly, also means the license allows unrestricted commercial use. MiniMax-M2 shipped under a modified-MIT license, but the newer M2.7 license restricts commercial use of the model or derivatives without prior written authorization. If M3 follows that precedent, expect downloadable weights with a non-commercial default and enterprise licensing available through direct sales. The technical report will settle this.
Who is making MiniMax M3?
MiniMax is a Shanghai-based AI lab founded in 2021. Outside China it is best known for its Hailuo video model, covered in our Hailuo 02 review, and for the M-series of language models. The company shipped M1 in mid-2025 (456B parameters) before pivoting to the smaller, denser, more agentic M2 family, and now M3.
The commercial backdrop adds weight to this launch. MiniMax listed on the Hong Kong Stock Exchange on January 9, 2026, so it is now a public company trying to prove it can sell model access, grow developer adoption, and still feed the open-source ecosystem. That is a hard balance: open weights build trust and distribution, but hosted APIs and agent subscriptions are where recurring revenue lives. The public face of the M3 work has been Skyler Miao (@SkylerMiao7), MiniMax’s Head of Engineering, whose X posts previewed the architecture before launch.
What MiniMax M3 means for the global AI race
Two shifts come into focus now that M3 has shipped.
First, sparse attention is back on the table for long-context production systems. MiniMax called it not-yet-ready in 2025. Leading with it now signals the broader field has catching up to do. Anthropic, Google DeepMind, and OpenAI all have efficient-attention research underway, but none have shipped a flagship with this kind of public efficiency commitment.
Second, Chinese open-weight labs keep widening the cost advantage. DeepSeek opened this front, Qwen kept the pressure on, and M3 raises it again: cheap to run, open to download, and now genuinely competitive on coding, context, and multimodal work at the same time. The U.S. labs’ pricing premium gets harder to defend with each launch. For the latest snapshot of where every flagship sits, see our Best AI rankings.
Should you switch to MiniMax M3?
If your workload needs 1M-token context, things like whole-codebase analysis, multi-document research agents, or long-running session memory, M3 is the obvious model to test first. That is the exact case it was built for, and the efficiency gains are what make those workloads affordable.
If you run standard agent or coding pipelines, it is worth piloting M3 against your current model, but wait for independent benchmarks and the technical report before betting production on the launch numbers. The smart move is to test the hosted model now and re-evaluate once the weights are public.
If you just want to test multiple Chinese and Western flagship models without juggling separate API keys, the Fello AI app for Mac and iOS routes between Claude, ChatGPT, Gemini, Grok, and DeepSeek through one interface. M3 landed in Fello AI with the 6.7.0 update, so it now sits in the same interface as those models.
What to watch next
The next few weeks decide how much of the launch survives outside testing. Three things to watch: the open weights and technical report landing on Hugging Face within the promised ten days, the first independent benchmark runs that strip away MiniMax’s own scaffolding, and M3’s eventual appearance on neutral boards like DeepSWE. If those arrive cleanly, MiniMax will have done more than ship another capable model. It will have made the frontier race harder for every lab selling coding agents. We will keep this article updated as the verified data comes in.
FAQ
Is MiniMax M3 out yet?
Yes. MiniMax officially released M3 on June 1, 2026. It is available now through the API, monthly token plans, and the MiniMax Code agent product. Open weights and a technical report are expected on Hugging Face and GitHub within about ten days.
Is MiniMax M3 open source?
It is open-weight, with weights and a technical report promised within roughly ten days of launch. Whether it is fully open-source depends on the license. If M3 follows the M2.7 precedent, weights will be downloadable but commercial use may require written authorization from MiniMax.
How fast is MiniMax M3?
At 1-million-token context, MiniMax says M3’s MSA architecture uses one-twentieth the per-token compute of the prior generation, with more than 9× faster prefill and more than 15× faster decoding. Output runs around 100 tokens per second.
How good is MiniMax M3 at coding?
MiniMax reports 59.0% on SWE-Bench Pro, beating GPT-5.5 and Gemini 3.1 Pro and approaching Claude Opus 4.7. Several results were run on MiniMax’s own infrastructure with agent scaffolding, so wait for independent verification before treating them as final.
How much does MiniMax M3 cost?
API input pricing starts around $0.30 per million tokens, dropping to a blended ~$0.06 per million with cache optimization. Monthly token plans run $20 (Plus), $50 (Max), and $120 (Ultra). That makes M3 more than 15× cheaper on input than Claude Opus 4.7.




