
Google, the well-known tech giant, has joined the AI race with the introduction of its Gemini AI suite. The Gemini AI suite was officially announced during the Google I/O keynote on May 10, 2023. This announcement marked the introduction of Gemini as a successor to Meta’s previous models, such as LaMDA and PaLM 2 and a direct competitor to OpenAI’s GPT-4.
The first version, Gemini 1.0, was launched on December 6, 2023, and included several models, such as Gemini Ultra, Gemini Pro, and Gemini Nano, tailored for different use cases and capabilities.
Gemini 1.5 Pro is the latest iteration of this powerful large language model (LLM).
With its advanced natural language processing, multimodal interaction, and creative content generation capabilities, Gemini 1.5 Pro is among the best generative AIs available, redefining human-computer interaction.
Gemini 1.5 Pro is not just another AI model; it is a sophisticated ecosystem that integrates seamlessly with existing Google services, which by so creates a seamless user experience across Google’s products.
The model is built on advanced neural network architectures, specifically optimized for multimodal tasks. It can process and understand text, images, audio, and video.
This comprehensive guide will delve into Gemini 1.5 Pro’s capabilities, history, and future prospects, as well as compare it to other leading AI models in the market.

Overview of Gemini 1.5 Pro
Gemini 1.5 Pro is a state-of-the-art generative AI model that excels in various tasks, from text generation to image recognition and coding assistance.
Google developed this GenAI, and this LLM is built to be multimodal, meaning it can seamlessly process and generate content across various formats, including text, images, audio, and video.
With a large context window and a knowledge cutoff date of November 2023, Gemini 1.5 Pro is equipped with up-to-date information to provide accurate and relevant responses. Let’s now explain this further.
Key Specifications
- Model Size: Gemini 1.5 Pro features a large parameter count of over 200 billion parameters, allowing it to capture complex language patterns and generate nuanced text. This extensive parameter count significantly enhances the model’s ability to understand and generate high-quality outputs.
- Context Window: The model supports a context window of 128,000 tokens, enabling it to maintain coherence over lengthy interactions and manage extensive conversations effectively. Notably, Gemini 1.5 Pro can also operate with a two-million-token context window for enterprise customers, which is one of the longest context windows available in any large-scale foundation model.
- Knowledge Cutoff: Gemini 1.5 Pro’s knowledge cutoff date is November 2023, which ensures that it incorporates the latest information and developments in various fields. This makes it particularly relevant for users seeking current data.
- Multimodal Capabilities: The model can process and generate content across multiple formats, including text, images, audio, and video. This multimodal capability allows Gemini to perform complex tasks that require understanding and integrating different types of information.
- Users can generate:
- Text: Articles, reports, and marketing copy that can be used in blogs, newsletters, and social media.
- Images: Visual content based on descriptive text for creative projects, such as illustrations for books or graphics for advertisements.
- Audio: Voiceovers and soundscapes for multimedia presentations. Mostly used for enhancing the auditory experience of videos and interactive content.
- Video: Short video clips or animations that combine text and visuals for storytelling, ideal for low-budget marketing campaigns and educational materials.
- Users can generate:
Company Background
Google, the tech giant behind Gemini, has been at the forefront of AI research and development for years. Google has been a pioneer in artificial intelligence (AI) research and development long before the launch of its Gemini AI suite.
Starting in the early 2000s, Google began integrating machine learning and AI technologies into its products, significantly enhancing user experiences. For instance, in 2004, Google introduced its PageRank algorithm, which utilized AI techniques to improve search results by ranking web pages based on their relevance and authority.
This foundational technology laid the groundwork for future AI advancements at Google. Over the years, Google has continued to innovate, launching several AI-driven features across its platforms.
In 2016, the company introduced Google Assistant, a virtual assistant that leverages natural language processing (NLP) to understand and respond to user queries.
In 2018, Google unveiled BERT (Bidirectional Encoder Representations from Transformers), an NLP model that significantly improved the understanding of context in search queries.
These advancements exemplify Google’s commitment to integrating AI into its services. This ultimately led to the development of the Gemini AI suite, which was officially announced in May 2023.
With a strong focus on innovation and a commitment to ethical AI practices, Google is undoubtedly a leader in the field of artificial intelligence.
The company’s extensive resources and expertise in machine learning have enabled it to create powerful AI models that push the boundaries of what is possible.
Gemini is the culmination of collaborative efforts across various Google teams, including Google Research and DeepMind. The model was built from the ground up to be multimodal, allowing it to generalize and seamlessly understand, operate across, and combine different types of information, as mentioned above.
Capabilities of Gemini 1.5 Pro
Gemini 1.5 Pro boasts a wide range of capabilities that make it a versatile tool for various applications:
Natural Language Processing and Generation: The model understands complex queries and generates coherent, contextually relevant responses. It can assist with tasks such as drafting emails, writing articles, and creating content for various platforms. Its ability to manipulate language allows it to craft creative texts like poems and scripts while adapting its style and tone to suit the desired context.
Multimodal Interaction: The model is also designed to interpret and respond to various types of content. This multimodal capability enables it to engage in more natural and intuitive user interactions, making it suitable for applications like virtual assistants and interactive chatbots.
Image Generation: One of Gemini 1.5 Pro’s standout features is its ability to generate images based on textual descriptions. This capability opens up new possibilities for creative applications and visual storytelling, allowing users to create unique visuals that complement their written content.
Coding Assistance: The model can assist developers by writing, debugging, and optimizing code. In internal evaluations, Gemini 1.5 Pro has demonstrated high accuracy in generating functional code snippets, outperforming many existing AI coding assistants. Its understanding of programming languages and ability to solve coding challenges make it a valuable tool for software engineers
Multilingual Processing: Gemini 1.5 Pro supports more tha 40 languages, enabling users from diverse backgrounds to interact with the model in their preferred language. This feature is particularly useful for global businesses and organizations, as it facilitates seamless communication across language barriers. The model’s multilingual capabilities are backed by its training on a vast corpus of multilingual data.
Question Answering and Information Retrieval: The model can also uniquely answer challenging, open-ended questions and provide comprehensive and informative responses. It can retrieve relevant information from its vast knowledge base, swiftly providing users with the necessary insights.
History of the Gemini Model Family
Gemini 1.5 Pro is part of a lineage of models that began with Gemini 1.0. Each iteration has introduced improvements in performance, safety, and usability:
Gemini 1.0: The initial model focused on establishing a solid foundation for multimodal interaction and natural language processing. It was built to understand and generate text while incorporating basic image processing capabilities.
Gemini 1.1: This version introduced enhanced image generation capabilities, allowing users to create visual content based on textual descriptions. It also improved the model’s overall performance in language tasks, achieving higher accuracy in various benchmarks.
Gemini 1.5: The latest iteration, Gemini 1.5, builds on its predecessors by offering improved performance, expanded language support, and enhanced safety measures, especially following its racism and bias accusations. It has been tested against various benchmarks, including the Massive Multitask Language Understanding (MMLU) test, where it achieved scores exceeding 85% in general knowledge across 57 subjects.
Gemini 1.5 Flash: Launched in late 2024, Gemini 1.5 Flash introduced real-time capabilities, allowing users to interact with the model more dynamically. This version enhanced the model’s ability to process live data and respond to user inputs with minimal latency. It is a powerful tool for applications requiring immediate feedback.
Use Cases for Gemini 1.5 Pro
Gemini 1.5 Pro can be applied in various domains, including:
Content Creation: The model can assist in generating articles, reports, and marketing materials, significantly reducing the time required for content production. It is valuable for writers and marketers as it can help them generate high-quality text for niche and general use.
Creative Applications: Gemini 1.5 Pro’s image generation capabilities suit visual storytelling, product design, and artistic expression applications. Users can create compelling visuals that enhance their creative projects, such as marketing campaigns and social media content.
Education: Educators can leverage Gemini to create interactive learning materials, quizzes, and presentations. The model’s ability to generate explanations and summaries can aid in teaching complex concepts, making it an effective tool for personalized and self-paced learning.
Customer Support: The model can be integrated into customer service platforms to provide efficient and personalized support, answer inquiries, and resolve issues quickly. It’s one of its best use cases.
Software Development: Developers can utilize Gemini’s coding capabilities to streamline workflows, automate repetitive tasks, and improve code quality. It is a great coding tool that can assist in generating code snippets and debugging errors.
Global Communication: With its multilingual processing capabilities, Gemini 1.5 Pro can facilitate communication across diverse cultures and languages, making it an invaluable tool for international businesses.
Comparative Analysis
This section provides a detailed comparison of Gemini, ChatGPT, Claude AI, and LLaMA 3.1, highlighting their key differences and performance across various dimensions.

Gemini vs. ChatGPT
- Model Architecture: Gemini is designed with a native multimodal architecture, allowing it to process and generate content across various formats, including text, images, audio, and video. In contrast, ChatGPT primarily focuses on text-based interactions but excels better in conversational contexts.
- Parameter Count: Gemini 1.5 Pro has over 200 billion parameters, while ChatGPT (GPT-4) is estimated to have around 175 billion parameters. This gives Gemini a slight edge in terms of complexity and potential performance.
- Mathematical Reasoning: ChatGPT has been noted for its accuracy in tests involving mathematical reasoning, often providing precise answers to complex problems. Gemini, while capable, has shown variability in its mathematical outputs, sometimes requiring additional prompts to clarify its responses.
- Code Generation: Both Gemini and ChatGPT perform well in coding tasks, but Gemini has demonstrated a stronger ability to provide explanations and tips alongside the generated code. This greatly enhances the learning experience for users seeking to understand coding concepts with these tools.
Gemini vs. Claude AI
- Focus and Strengths: Gemini is known for its multimodal capabilities, making it suitable for various applications, as mentioned above. Claude AI, on the other hand, is designed with an emphasis on safe and user-aligned interactions, excelling in conversational applications and ethical considerations.
- Performance on Benchmarks: Gemini has shown strong performance on various benchmarks, particularly in general reasoning and comprehension tasks. Claude AI, however, often outperforms Gemini in creative tasks and human-like conversational abilities. It is a preferred choice for applications requiring a more nuanced understanding of user intent.
- Safety and Alignment: Claude AI is built with a focus on safety and alignment with user intentions, which is crucial for applications in sensitive sectors like healthcare and finance. Gemini, while also incorporating safety measures, is more geared towards providing informative data and handling diverse content types.
Gemini vs. LLaMA 3.1
- Model Size: LLaMA 3.1 boasts 405 billion parameters, significantly larger than Gemini’s 200 billion parameters. This size advantage allows LLaMA to capture more intricate language patterns and generate richer content. LLaMa excels here only because of a larger parameter; if it meant Gemini was the same, Gemini would excel better.
- Context Window: Both models feature a context window of 128,000 tokens, and it enables them to maintain coherence over lengthy interactions. This similarity specifically allows for effectively handling extended conversations and complex queries.
- Multimodal Interaction: Gemini excels in multimodal capabilities, particularly in generating images from text descriptions. LLaMA 3.1 has some image generation capabilities, but they are more limited compared to Gemini’s advanced features, which include real-time access to the internet for sourcing images.
- Integration and Ecosystem: Gemini has been integrated into various Google products, and it enhances the ecosystem’s functionality with AI-driven features. In contrast, LLaMA 3.1’s open-source nature allows for broader experimentation and customization by developers.
Summary of Comparisons
In summary, each model brings unique strengths to the table:
- Gemini excels in multimodal capabilities and provides a user-friendly experience with features like response editing and real-time internet access.
- ChatGPT is highly effective for conversational tasks and provides a polished user experience, but lacks the customization options available with Gemini.
- Claude AI offers advanced visual reasoning and coding assistance but operates within a proprietary framework, limiting its adaptability.
- LLaMA 3.1 stands out for its large parameter count and open-source accessibility, and it also offers significant advantages in versatility and customization.
Ultimately, the choice between these models depends on specific use cases, desired features, and the level of customization required by developers and organizations.
Technical Specifications
Gemini 1.5 Pro is built on a robust neural network architecture that enables it to process and generate text efficiently. The model’s technical specifications include:
- Parameter Count: Gemini 1.5 Pro has a parameter count that exceeds 200 billion. This extensive parameter count significantly affects the model’s ability to understand and generate high-quality outputs.
- Context Window: The model supports a context window of 128,000 tokens, enabling it to maintain coherence over lengthy interactions. Additionally, Gemini can operate with a two-million-token context window for enterprise customers, making it one of the most flexible enterprise models available.
- Processing Speed: The model operates at high speeds, ensuring timely and responsive outputs even for complex tasks. This efficiency is crucial for applications requiring real-time interactions, such as customer support and interactive user interfaces.
- Safety Measures: Gemini 1.5 Pro incorporates advanced safety protocols, including content filtering and bias mitigation techniques, to prevent generating harmful or biased content.
- Training Infrastructure: Gemini models are trained on Google’s Cloud TPU v4 and v5e, which are specialized AI accelerators designed to handle extensive machine-learning tasks efficiently.
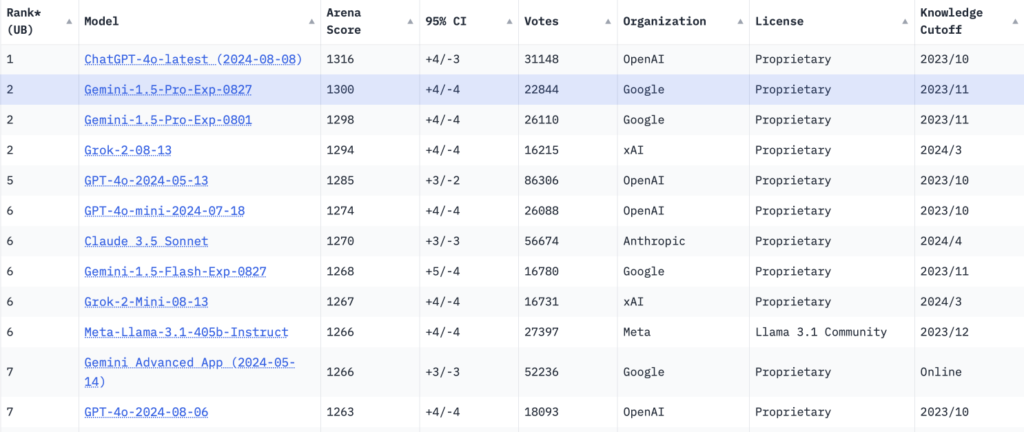
Future Outlook
The future of Gemini AI looks promising, with ongoing developments aimed at further enhancing its capabilities. Upcoming releases like Gemini 2.0 are expected to introduce even more advanced features, such as improved multimodal reasoning, enhanced memory capabilities, and expanded language support.
FAQs
Can Gemini AI generate images? Yes, Gemini 1.5 Pro can generate images based on textual descriptions.
Who owns Gemini AI? Gemini AI is owned and developed by Google, a leading technology company known for its innovations in artificial intelligence.
Where to download Gemini AI? Gemini AI is not currently available for direct download, but users can access it through various Google platforms and services.
Can Gemini AI be used without logging in? While the official Gemini AI web app requires users to log in, there are third-party platforms, such as Fello AI, that allow users to interact with Gemini AI without the need for a login.
What’s the difference between Gemini AI and Google Assistant? Gemini AI is a more advanced and capable large language model that can handle various tasks, including multimodal interaction and image generation. Google Assistant, on the other hand, is a virtual assistant focused on providing quick answers and performing basic tasks.
When is Gemini 2.0 coming? Google has yet to announce a specific release date for Gemini 2.0, but according to multiple sources, it is expected to be launched later this year. It will build upon the success of Gemini 1.5 Pro and introduce even more advanced features and capabilities.




