
Can an open-source AI really outsmart billion-dollar giants? Meet DeepSeek-R1, a groundbreaking model from China that’s turning heads worldwide. It recently scored an astonishing 97.3% on MATH-500, a math benchmark that leaves most competitors in the dust, and hit a 96.3% percentile on Codeforces, putting its programming skills on par with human experts.
What’s even more surprising is that DeepSeek-R1 is fully open-source and costs a fraction of traditional models to train and deploy. With its reinforcement learning-based architecture and MIT license, it’s challenging the dominance of proprietary systems like OpenAI’s o1 and Google’s Gemini 2.0.
This is more than just another AI release—it’s a revolution in accessibility, affordability, and performance. Dive into the story of how DeepSeek-R1 is rewriting the rules of AI innovation and putting cutting-edge tools into the hands of anyone willing to try.
DeepSeek’s app raises serious privacy and security issues by transmitting user data, including chat logs and keystrokes, to servers in China. This data is subject to Chinese laws, which may compel companies to share information with the government.
For a safer alternative to DeepSeek’s app, users can host its open-source models locally or use 3rd party platforms which keep data within Western data centers, avoiding Chinese data risks and censorship.
Story of R1
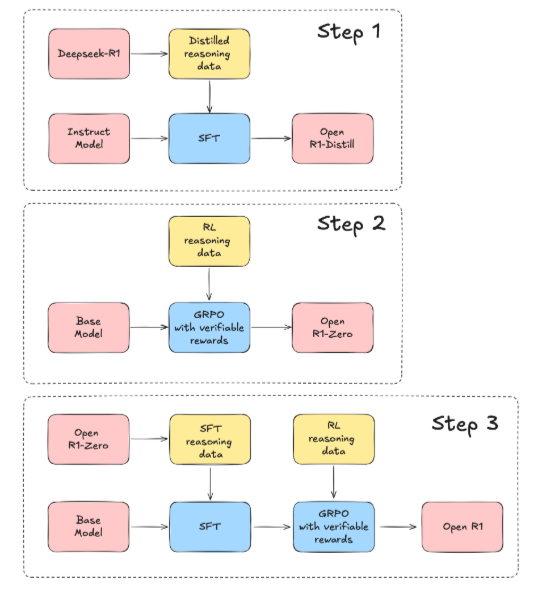
DeepSeek-R1 was developed by DeepSeek, a company that originated as a small research team in Hangzhou, China. This dedicated group of AI researchers aimed to challenge the status quo of large language models (LLMs). Frustrated by proprietary systems that demanded massive resources and locked intellectual property behind restrictive licenses, the team set out to build a model that combined high performance with open accessibility.
Their initial goal was bold: to create an LLM that excels in math, coding, and logical reasoning—without relying on billions of labeled examples. Instead, they turned to reinforcement learning, enabling the model to learn through trial-and-error interactions. This approach was initially met with skepticism, but the team persisted. Gradually, they incorporated a “cold start” fine-tuning phase, ensuring that the model produced coherent, human-readable answers from day one.
Through multiple iterations, the project evolved into DeepSeek-R1—a model that started to beat established benchmarks and rival the output quality of heavily-funded corporate AI labs. The team’s decision to release the model under an MIT license was not just a technical move but a philosophical stance: they believed in democratizing AI to accelerate innovation worldwide.
By late 2024, DeepSeek-R1 was no longer just an experimental project in Hangzhou’s tech circles. News of its impressive performance began circulating in international research communities. Some hailed it as the “open-source AI breakout,” while others were intrigued by its cost-effective training methods. Either way, DeepSeek-R1 had arrived on the global stage, and it was clear that its story was only just beginning.
Technical Overview
DeepSeek-R1 stands out not just for its open-source philosophy but for its remarkable technical capabilities. Here’s a closer look at what makes it so impressive, from its performance benchmarks to its innovative training approach.
Performance Across Domains
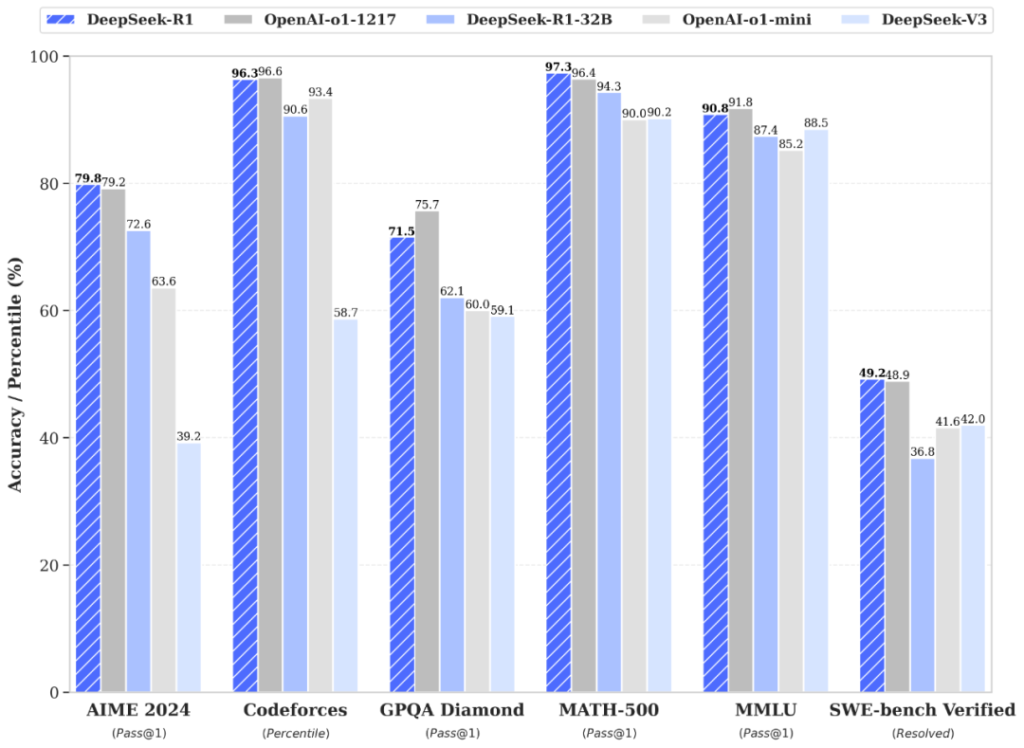
DeepSeek-R1 has delivered eye-catching results across several respected benchmarks. For example, it achieved an incredible 97.3% on MATH-500, leaving most competitors behind. Similarly, its 96.3% percentile on Codeforces demonstrates near-human coding abilities, making it a strong contender for programming tasks.
Even in academic competitions like AIME 2024, DeepSeek-R1 excelled with 79.8% accuracy, edging out a comparable OpenAI model at 79.2%. These results highlight its ability to handle complex reasoning, math, and logic-heavy tasks with precision.
Open-Source Accessibility
One of the defining features of DeepSeek-R1 is its MIT open-source license, making it free for anyone to use, modify, and even commercialize. This accessibility means that researchers, educators, and businesses worldwide can leverage its capabilities without paying hefty licensing fees.
This open approach fosters innovation by encouraging collaboration. Developers can study its inner workings, customize it for specific needs, and contribute improvements. It’s a sharp contrast to proprietary systems that keep their core technology locked away.
DeepSeek-R1’s affordability is another key strength. Its API pricing is refreshingly low, charging $0.14 per million input tokens (cache hits) and $2.19 per million output tokens, far cheaper than most alternatives.
These cost savings lower the barrier for entry, allowing startups, small businesses, and independent developers to integrate advanced AI tools without draining their budgets. Whether for tutoring apps, customer support bots, or research tools, DeepSeek-R1 makes cutting-edge AI practical for everyone.
Reinforcement Learning
At its core, DeepSeek-R1 uses reinforcement learning (RL) to train itself, making it less dependent on vast labeled datasets. The model learns through trial and error, gradually improving its problem-solving and reasoning skills.
The development team also introduced a “cold start” phase, where the model was pre-trained on high-quality data to ensure clarity and coherence from the outset. This combination of RL and fine-tuning has helped it excel in tasks like multi-step math problems and complex coding challenges.
Fine-Tuning
DeepSeek-R1 addresses common AI issues like confusing responses or mixed-language outputs by employing targeted fine-tuning. Early training phases included curated datasets that ensured the model could generate accurate, readable responses consistently.
This careful preparation means DeepSeek-R1 is ready for practical applications, from education to content creation. It’s built not just to impress in benchmarks but to perform in real-world scenarios.
Distilled Versions
For those without access to industrial-scale hardware, DeepSeek-R1 offers distilled versions. These smaller variants, like the 32-billion-parameter model, maintain most of the original’s capabilities while being far easier to run. The 32B model, for example, scored an impressive 94.3% on MATH-500, just slightly behind the full version. These scaled-down models make it possible for smaller teams or individual researchers to work with advanced AI tools without requiring high-end infrastructure.
Taking on the Heavyweights
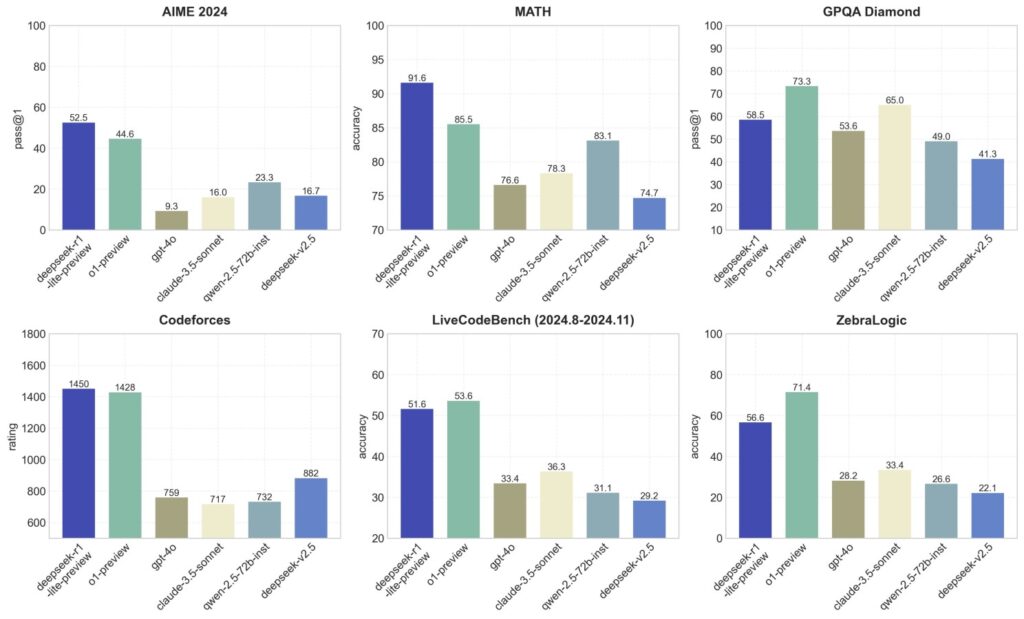
DeepSeek-R1 is more than just an impressive open-source project—it’s a direct challenge to AI powerhouses like OpenAI, Google, and Anthropic. On benchmarks like math and coding, it often rivals the best proprietary systems. While it doesn’t always outperform the latest offerings like OpenAI’s o1, the gap is surprisingly narrow for a model that costs 1/20th as much to train and is completely open-source under an MIT license.
In tasks such as reasoning, math, and coding, DeepSeek-R1 holds its own or comes close to OpenAI’s o1. According to tests, it matches o1-preview in reasoning and creative writing while slightly trailing in coding and mathematics. However, its writing outputs feel notably freer, less censored, and more creative, making it an excellent option for those seeking a model with personality and flexibility. Unlike heavily fine-tuned proprietary models, R1 allows for more exploration and creative problem-solving, giving it a unique edge in areas that require originality.
How It Stacks Up
- Reasoning: DeepSeek-R1 is a reasoning powerhouse, standing out in complex multi-step tasks that stumped previous state-of-the-art models. While OpenAI’s o1 remains slightly ahead, R1 outperforms earlier benchmarks and offers comparable depth and coherence in its logic-driven responses.
- Mathematics: On math-specific benchmarks like MATH-500, R1 remains competitive, scoring 97.3%, which is impressive given its reduced computational costs. Though OpenAI’s o1 has a slight edge in pure mathematical tasks, R1’s efficiency makes it a practical choice for organizations on a budget.
- Coding: When tested on coding challenges like Codeforces, DeepSeek-R1 shows near-human proficiency, scoring 96.3% percentile. While o1 has a marginal advantage in generating optimized code, R1 closes the gap with cost-effectiveness and its ability to be distilled into smaller models for broader accessibility.
- Writing: One area where R1 shines is creative writing. Its outputs have been described as more natural, free-flowing, and engaging, similar to early iterations of open models like Opus. Unlike the rigid, rule-bound responses of some proprietary systems, R1’s responses often feel more human, giving it a clear lead in this domain.
DeepSeek-R1 has disrupted the AI field by rivalling proprietary giants like OpenAI while being significantly cheaper and fully open-source. Its innovative training pipeline, using pure reinforcement learning (GRPO) and fine-tuning techniques like “aha moments” and rejection sampling, shows that smaller teams can achieve remarkable results without massive resources. By offering transparency, affordability, and adaptability, DeepSeek-R1 isn’t just competing—it’s redefining the future of open AI.
Where It Goes from Here
DeepSeek-R1 has made a bold entry into the AI world, but its journey is far from over. While it holds incredible promise, there are hurdles to overcome and opportunities waiting to be unlocked.
Current Hurdles
Despite its achievements, DeepSeek-R1 isn’t perfect. Early versions struggled with multi-turn conversations, often leading to repetitive or confusing responses.
Another significant concern is the potential for misuse. Being open-source means anyone can modify and deploy it, including for harmful purposes. The DeepSeek team has acknowledged this and emphasizes the need for community guidelines and responsible usage to mitigate risks.
New Possibilities
On the other hand, DeepSeek-R1’s open nature could spark rapid innovation. Developers, startups, and universities worldwide can experiment and refine the model, whether by improving its code generation or tailoring it for specific languages and cultural contexts.
This global collaboration has the potential to bring AI benefits to underserved communities. Imagine better healthcare diagnostics in rural areas or educational tools customized for local needs—DeepSeek-R1 makes such applications more achievable than ever.
Future Outlook
DeepSeek’s plans include further enhancing its reinforcement learning pipeline, enabling the model to handle more complex, real-world dialogues with ease. They’re also exploring fine-tuning for niche domains like scientific research, financial analytics, and legal documents.
As the open-source community continues to test, improve, and expand DeepSeek-R1, it’s likely to grow even more versatile and robust. If the model can maintain or surpass its current benchmark performance while addressing issues like misuse and model drift, it could become a landmark in collaborative AI development.
DeepSeek-R1 isn’t just another AI—it’s a shift toward cost-effective, accessible, and innovative AI for everyone. Whether you’re a developer, entrepreneur, or policymaker, this model is one to watch.
Conclusion
DeepSeek-R1 isn’t just another entry in the AI race—it’s a bold statement that high-performing models don’t have to come from billion-dollar labs or come wrapped in proprietary restrictions. With its open-source MIT license, cutting-edge performance in reasoning, math, coding, and writing, and a fraction of the training cost compared to giants like OpenAI, this model represents a turning point in the evolution of artificial intelligence.
Its success showcases the potential of reinforcement learning combined with strategic fine-tuning, proving that smaller teams with innovative approaches can compete with the largest players in the industry. While it faces challenges, such as mitigating misuse and refining multi-turn interactions, its open nature ensures a global community can come together to address these issues and push its capabilities even further.
DeepSeek-R1 is more than an AI—it’s a movement toward democratizing artificial intelligence, breaking down barriers, and enabling innovation for everyone. Whether you’re a researcher, a developer, or an entrepreneur, DeepSeek-R1 offers an exciting glimpse into a future where cutting-edge AI isn’t just for the few—it’s for the world.




