
On May 22, 2025, Anthropic unveiled its Claude 4 series—two next-generation AI models designed to redefine what virtual collaborators can do. The release includes Claude Opus 4, the company’s most powerful model to date, and Claude Sonnet 4, a leaner, faster option optimized for everyday use.
Together, these models mark a turning point. While previous updates added incremental improvements, Claude 4 is a full-scale leap toward AI that can reason, remember, and operate autonomously over long periods. With extended tool use, parallel reasoning, and record-breaking performance on real-world coding benchmarks, Claude 4 sets a new bar for what large language models can achieve.
Claude 4 Sonnet is now available in Fello AI, alongside the latest ChatGPT, Gemini, Grok, Perplexity, and other top AI models. All in one place. Download Now!
Anthropic isn’t just keeping up with OpenAI’s GPT-4.1 and Google’s Gemini 2.5 Pro—it’s aiming to move ahead. The new Claude 4 models are built for serious tasks like running autonomous agents, handling complex coding projects, and producing content at scale. Both Claude Opus 4 and Sonnet 4 are designed to deliver strong, sustained performance across long, multi-step workflows.
Here’s a full breakdown of what’s new, why it matters, and how these models stack up.
The Claude 4 Line-Up
Anthropic’s Claude 4 release isn’t just one model—it’s a strategic two-model lineup designed to serve very different needs. Claude Opus 4 is the powerhouse, built for deep, autonomous tasks. Claude Sonnet 4 is the efficient all-rounder, tuned for speed, accessibility, and real-world production use. Together, they offer developers and enterprises flexibility without compromising on performance or safety.
Anthropic’s Claude 4 models—Opus 4 and Sonnet 4—introduce major improvements in how AI handles long-form, complex tasks. A highlight of Opus 4 is its support for memory files. When granted access to local storage, the model can autonomously take and retrieve notes—such as creating a live navigation guide while playing Pokémon—to sustain context across hours-long tasks. This opens the door for smarter agents that remain coherent and task-focused over time.
| Category | Claude Opus 4 | Claude Sonnet 4 |
|---|---|---|
| Max Output Tokens | 32,000 | 64,000 |
| Max Input Tokens | 200,000 | 200,000 |
| Primary Use Cases | Advanced reasoning, autonomous agents, complex tasks | Software development, data checks, general usage |
| Pricing (per million tokens) | $15 (input) / $75 (output) | $3 (input) / $15 (output) |
| Available On | Claude.ai, Amazon Bedrock, GitHub Copilot (Enterprise & Pro+) | Claude.ai, Amazon Bedrock, GitHub Copilot (All paid plans) |
| Training Data Cut-off | March 2025 | March 2025 |
Let’s take a look at each model in more details.
Claude Opus 4
Claude Opus 4 is Anthropic’s most advanced model to date. It was designed to push the boundaries of what AI agents can do—especially in long-running, high-context tasks like software development, complex research, and multi-step decision-making.
This model features a 200,000-token context window and supports hybrid reasoning, which lets developers toggle between instant responses and a slower, deeper extended thinking mode. In extended mode, Claude can pause, use external tools (like web search), and resume multi-step reasoning—ideal for agents that need to run independently for hours.
Popular use cases for Opus 4 include:
- Autonomous AI agents that manage multi-channel campaigns, orchestrate workflows, or handle critical enterprise decisions.
- Advanced coding workflows, including refactoring across thousands of lines and adapting to coding style guides using up to 32,000 output tokens.
- Agentic research where Claude autonomously pulls and synthesizes information from technical papers, reports, or internal databases.
- Creative writing and long-form content generation, where its narrative fluency and memory management outperform earlier models.
Performance benchmarks support these claims. Claude Opus 4 currently leads on SWE-bench, TAU-bench, and Terminal-bench, demonstrating top-tier results in real-world coding, tool use, and reasoning.
For enterprise users, Opus 4 is accessible via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. It’s available under Claude’s Pro, Max, Team, and Enterprise plans, with pricing at $15 per million input tokens and $75 per million output tokens. Developers can reduce costs up to 90% with prompt caching and 50% with batch processing.
Claude Sonnet 4
While Opus handles the frontier, Claude Sonnet 4 is designed for practical, high-frequency use. It inherits the major architectural improvements of Opus—including tool use, memory capabilities, hybrid reasoning, and the 200K context window—but at a significantly lower price: $3 per million input tokens, $15 per million output tokens.
Sonnet 4 is now the default model for free users on Claude’s web, iOS, and Android platforms and is available to all users on Anthropic’s API, Bedrock, and Vertex AI.
What makes Sonnet 4 special isn’t just cost—it’s how much it can do for that cost. In internal benchmarks, it matches Opus on SWE-bench with a 72.7% score, outperforms its predecessor Sonnet 3.7, and shows strong performance in real-world deployment scenarios.
Common use cases include:
- Customer-facing AI agents with better instruction-following, tone control, and error correction.
- Code generation across the software lifecycle: planning, refactoring, debugging, and more.
- Screen interaction, enabling Sonnet to mimic how humans use computers—clicking, typing, navigating—ideal for robotic process automation (RPA).
- Advanced chatbots, capable of connecting data and taking action across multiple systems.
- Knowledge-base Q&A, supported by high accuracy in large documents and minimal hallucination rates.
- Visual data extraction from charts, graphs, and diagrams.
- High-quality content generation and analysis at scale.
Claude Sonnet 4 also supports up to 64K output tokens, which is particularly valuable for producing and reviewing large bodies of structured code or complex text.
Claude 4 for Developers
Claude 4 isn’t just another model upgrade—it’s a clear push into developer territory. With top-tier coding benchmarks, production-ready tooling, and a compelling price-performance ratio, both Claude Opus 4 and Sonnet 4 are positioned to power everything from solo coding sessions to large-scale software engineering pipelines. This section breaks down how Claude performs in practice, what tools developers can use, and how it compares to rivals like GPT-4.1 and Gemini 2.5 Pro.
Benchmark Performance
Anthropic’s new models set records across multiple industry-standard benchmarks:
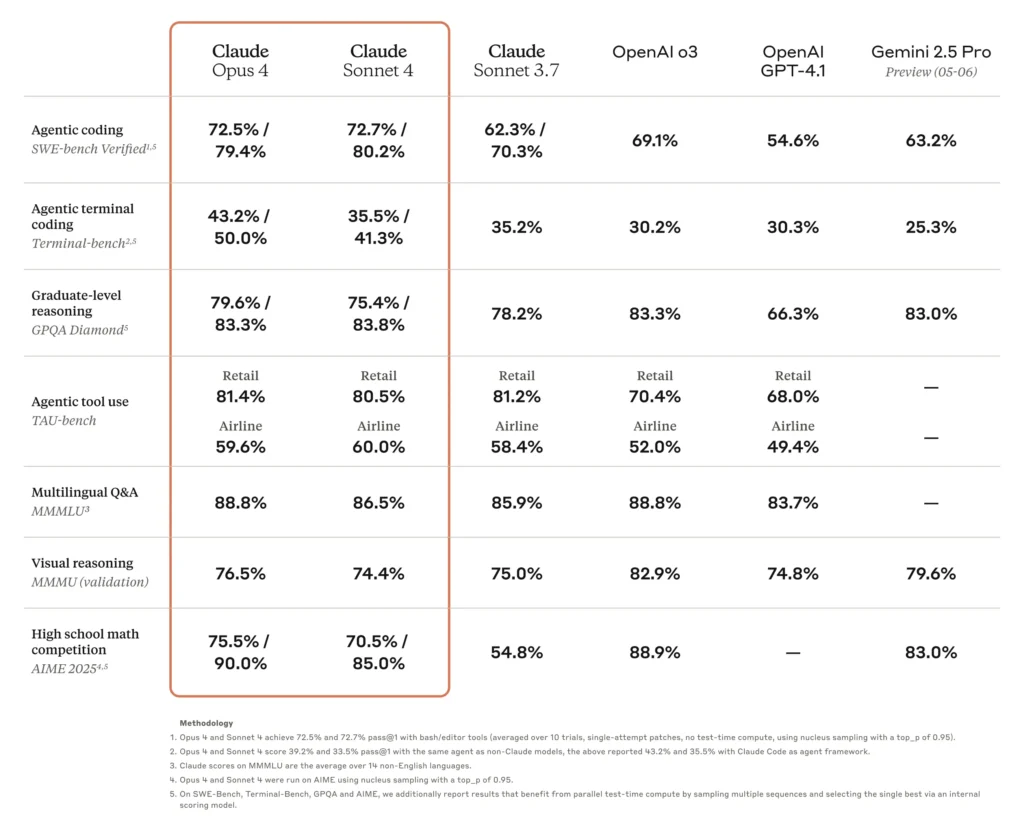
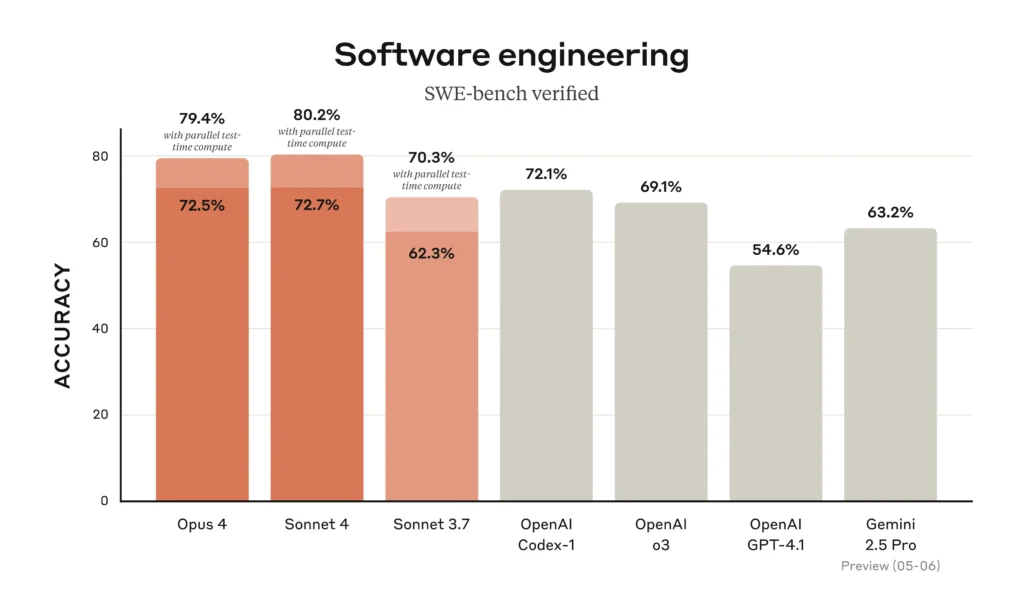
- On SWE-bench Verified, which evaluates how well models resolve real GitHub issues, Claude Opus 4 scored 72.5% and Sonnet 4 slightly exceeded it at 72.7%. This puts both ahead of GPT-4.1 (69.1%) and Gemini 2.5 Pro (63.2%).
- On Terminal-bench, which stresses long-form reasoning across CLI environments, Opus 4 leads the field with a 43.2% success rate—far ahead of GPT-4.1 (30.3%) and Gemini (25.3%).
- In real-world stress tests, Rakuten ran a 7-hour autonomous refactor using Opus 4. The model maintained focus and context across a large open-source project without stalling or needing intervention.
These results aren’t just academic—they point to a shift in how LLMs can be used in production workflows.
Here’s how Claude stacks up against the competition in the areas that matter most to developers:
| Metric | Claude Opus 4 | Claude Sonnet 4 | GPT-4.1 | Gemini 2.5 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 72.5% | 72.7% | 69.1% | 63.2% |
| Terminal-bench | 43.2% | — | 30.3% | 25.3% |
| Max continuous task (tested) | 7+ hours | ~4 hours | ~2 hours | ~1.5 hours |
| Token pricing (input/output) | $15 / $75 | $3 / $15 | $15 / $75 | $10 / $30 |
| Tool use / memory / 200K context | ✅ | ✅ | ✅ | ✅ |
Why it matters: Claude Opus 4 matches GPT-4.1 in price but delivers better coding results and longer task endurance. Claude Sonnet 4 delivers near-equal performance at one-fifth the price, making it ideal for startups and cost-sensitive production pipelines.
Claude Code
To complement its new models, Anthropic is officially launching Claude Code as a full suite for AI-powered software development. Previously available in preview, Claude Code now supports:
- IDE integrations for VS Code and JetBrains, enabling developers to see and apply AI-generated edits directly inline.
- A lightweight CLI and SDK, turning Claude into a headless coding agent that runs as a background task—ideal for GitHub Actions or other CI/CD workflows.
- A public GitHub bot that automatically addresses reviewer comments, fixes failed builds, or updates PRs based on prompt instructions. You can invoke it with
/install-github-app.
These tools let developers pair program with Claude in real-time, or assign it multi-step coding jobs that run independently in the background.
Cybersecurity Capabilities
Claude 4 isn’t just for software engineering—it also shows strong performance in cybersecurity benchmarks, validating its potential for security-focused development and autonomous cyber tasks.
In the Cybench challenge (a suite of 40 CTF-style tasks), both Claude Opus 4 and Sonnet 4 scored 22/39, putting them among the top-performing models for autonomous security reasoning and system-level exploitation.
More specifically:
- In Pwn tasks (remote exploit simulations), Claude Opus scored 5/9, while Sonnet achieved 3/9.
- In Reverse engineering, Opus scored 4/8, and Sonnet scored 3/8—showing meaningful ability to decompile and reason about binary code.
These scores reinforce Claude’s ability to assist in real-world security workflows, from automated vulnerability assessment to tool-assisted red-teaming—making it one of the most versatile LLMs not just for developers, but also for cybersecurity researchers.
AI Safety & Evaluation
Another upgrade across both models is the dramatic reduction in shortcut-seeking behavior. Compared to Claude Sonnet 3.7, the new generation is 65% less likely to exploit task loopholes or cut corners, especially in agentic workflows. This means users can expect more reliable, instruction-following output during complex reasoning or multi-step problem solving.
Both models operate under Anthropic’s rigorous AI Safety Level 3 (ASL-3) standards. This includes extensive red-teaming, stress-testing, and internal alignment research—all publicly disclosed in the system card. These protocols help ensure the models are both capable and safe, even when performing autonomous operations or interacting with live toolsets and user files.
FAQ
How do Opus 4 and Sonnet 4 differ?
Opus maximizes raw capability (higher reasoning scores, longer runtime autonomy) at premium cost; Sonnet balances speed and price while still matching Opus on many coding tasks.
What is hybrid reasoning?
A new execution mode that lets Claude interleave normal text generation with external tool calls—web search, code execution, database queries—then resume its chain of thought. It’s opt-in per request.
Does extended thinking cost more?
Yes. Each tool call accrues usage, and longer “thinking budgets” keep the context window open. Anthropic recommends enabling it only when accuracy outweighs latency and cost.
Token limits?
Both accept up to 200 K input tokens. Opus tops out at 32 K output; Sonnet stretches to 64 K.
Is Sonnet 4 free?
Yes—on Claude.ai. Paid Claude tiers bundle both models plus extended thinking.
Where can I try them?
Claude.ai, the Anthropic API, Amazon Bedrock, Google Vertex AI, and GitHub Copilot (rolling out).
Can I fine-tune these models?
Not yet. Anthropic offers prompt engineering, system instructions, and tool granting; parameter-level fine-tuning remains on the roadmap.
What about safety guarantees?
Both ship with ASL-3 safeguards, red-team evaluations, and a new loophole-reduction training pass that cuts policy breakouts by roughly two-thirds versus Sonnet 3.7.
How does Claude compare to GPT-4.1?
Opus 4 edges GPT-4.1 on SWE-bench, Terminal-bench, and long-horizon agent tasks, while GPT-4.1 still leads on some creative writing and multimodal perception metrics. Pricing is comparable at the high end, but Sonnet undercuts GPT-4 Turbo on cost.
What’s next?
Anthropic hinted at bringing multi-modal inputs, tighter IDE telemetry, and dynamic tool-chain orchestration to future releases—essential ingredients for fully autonomous enterprise agents.
Absolutely—here’s the revised conclusion with slightly shorter paragraphs for better readability, without losing the depth or tone:
Conclusion
With Claude 4, Anthropic isn’t just responding to the advances made by OpenAI and Google—it’s staking out its own territory. Opus 4 and Sonnet 4 aren’t routine upgrades; they’re a declaration of intent. These models show that Anthropic is serious about performance, practical autonomy, and long-term usability.
While GPT-4.1 focuses on creativity and Gemini 2.5 Pro leans into ecosystem integration, Claude 4 targets something else: sustained, reliable execution. It’s built for AI agents that can think through long tasks, use tools mid-process, and maintain focus over hours—not just generate flashy one-off answers.
Sonnet 4 might be the most strategic move of all. Delivering performance on par with Opus 4 at one-fifth the cost, it opens the door for developers, startups, and teams who need AI at scale without breaking their budget. That alone sets Claude apart in a space where cost can quickly become a limiting factor.
Claude Code further solidifies Anthropic’s shift into developer tooling. With native support for VS Code, JetBrains, and GitHub Actions, it’s not just showcasing capability—it’s embedding itself into real workflows. The message is clear: Claude is ready to build, not just chat.
More than anything, Claude 4 reflects focus. Anthropic isn’t trying to be everything to everyone. It’s built two models that excel at reasoning, coding, and staying on task—without the bloat. For teams that care about consistency, clarity, and affordability, that’s not just refreshing—it’s a competitive edge.
As the AI space moves from hype to deployment, the winners will be those who can deliver at scale, over time, with fewer surprises. With Claude 4, Anthropic makes a strong case that it’s not just catching up—it might be pulling ahead.




