
The next evolution in artificial intelligence is almost here. GPT‑5 — developed by OpenAI — is shaping up to be the most capable, intelligent, and multimodal language model to date. In a recent OpenAI podcast, CEO Sam Altman revealed that it is expected to be released “later this summer”. But what exactly should we expect?
GPT-5 isn’t just about more parameters or raw power. It signals a fundamental shift in how AI systems are designed and used: from passive text generators to autonomous agents that can reason, adapt, and take action with unprecedented depth. This new generation will be able to operate across modalities (text, voice, image — and maybe even video), handle vastly longer context windows, and integrate memory and tools to support more complex, real-world tasks.
This article breaks down everything currently known about GPT‑5 — from how it compares to previous models to what its technical breakthroughs could mean for real-world use in research, education, coding, and AI automation.
GPT-5 Technical Innovations
GPT-5 is expected to introduce major upgrades in reasoning, memory, and modality — including the ability to process video natively, track user goals over time through persistent memory, and power more stable multi-step agents that can reflect, replan, and interact autonomously.
Here’s what’s likely coming:
Extended Context Window
For GPT‑5, expectations suggest we’ll see context windows extending to over 1 million tokens, which is a great leap from GPT‑4 Turbo’s current 128,000-token limit. This would allow the model to retain and reason over the equivalent of more than 10 full-length books, multi-threaded conversations with thousands of prior messages, or entire project histories.
This shift matters not just for summarization tasks, but also for maintaining state over time, enabling GPT-5 to support agents that persistently understand a user’s workflow, project history, or preferences across sessions. It opens the door to working with code repositories of entire apps, analyzing full-length medical studies and reports, reviewing hours-long videos, or reasoning over millions of data points — all within a single session.
Built‑In “Thinking Modes”
There’s growing speculation that OpenAI may adopt internal reasoning modes in GPT‑5, specialized compute paths or configurations optimized for different task types — similar to how other models (e.g., Gemini 2.5, Claude 4) switch minds or inference styles based on the request.
In a recent podcast, Sam Altman stated their intention to consolidate the o‑series and GPT‑series into one unified model that “knows when to think for a long time or not.” This points to a model capable of internally deciding whether to apply fast, shallow reasoning or deeper chain-of-thought reasoning — without requiring users to manually switch modes.
Part of this capability may come from adaptive reasoning strategies: GPT‑5 could switch between deductive logic for scientific analysis, lateral thinking for creative ideation, and heuristic shortcuts for real-time decisions. By matching the reasoning style to the problem type, the model could become both faster and more accurate in high-stakes or domain-specific contexts.
Alongside this, GPT‑5 may also include integrated execution modules optimized for specific cognitive tasks like code execution, multi-step math, or structured data parsing. Unlike external tools used in GPT‑4, these modules would be embedded directly within the model’s architecture, allowing it to offload sub-tasks to highly specialized internal components. This could lead to much higher accuracy and efficiency on problems that pure language modeling still struggles with — like logic puzzles, advanced math, or precise data manipulation.
Together, these upgrades would allow GPT‑5’s internal logic to manage multiple inference “paths” optimized for distinct user requests. This would bring a more intelligent, use‑case‑aware AI experience without requiring manual model switching.
Advanced Video Understanding
GPT-5 is expected to push beyond GPT-4o’s multimodal capabilities by treating video as a native input — not just sequences of images, but continuous streams with temporal context and semantic depth. This would allow the model to analyze long-form videos like lectures, tutorials, or security footage with awareness of scenes, dialogue, speaker intent, and evolving content over time.
Whether breaking down a knee replacement surgery step by step, identifying inconsistencies in witness testimony from a trial recording, extracting key takeaways from a two-hour university lecture, or flagging customer frustration cues in call center videos, GPT‑5 might become the first model truly able to “watch and understand” complex videos — a leap that brings AI closer to full-spectrum media comprehension.
Fine-Grained Personalization and Memory
While GPT-4 has introduced experimental memory – allowing the model to retain certain user preferences or facts between sessions – GPT‑5 is expected to take this further, especially within the ChatGPT product experience. Rather than storing isolated facts or temporary instructions, future versions of ChatGPT built on GPT‑5 may support structured, persistent user profiles: tracking goals, tone of voice, preferred formats, workflows, and even long-term projects.
This advancement would enable truly adaptive AI agents, ones that not only recall who you are, but also evolve with you over time. For students, a model that “knows” their syllabus, weak spots, and learning style. And for professionals, an assistant that tracks deadlines, suggests next steps, and aligns with your personal work regime — all without needing to be re-told every time.
Neural Modality Fusion Layer
GPT-5 may introduce a dedicated architecture layer that fuses multimodal inputs (text, image, audio) into a shared latent space. Unlike GPT-4o, where modalities are handled via add-ons or peripheral pathways, this would mean that vision and language are understood together at the core level. This fusion could allow, for example, GPT-5 to reason about diagrams and text jointly, or infer meaning from tone of voice and word choice in tandem — leading to truly holistic understanding.
Adaptive Multilingual Tokenization
GPT‑5 may employ a smarter tokenization system that dynamically adapts to each language’s structure. Unlike static byte-pair encoding, this approach could reduce token counts in complex or non-Latin languages like Czech or Arabic, improving both efficiency and accuracy. It may even use neural tokenizers trained to optimize representations across diverse languages during model training.
Stronger Support for Agent-Based Systems
GPT‑5 won’t be an autonomous agent itself, but it’s expected to be the most capable engine yet for powering agentic systems like AutoGPT or Devin. With longer context windows, improved memory, and stronger internal reasoning, GPT‑5 addresses core weaknesses in current agents — such as poor task tracking, inconsistent planning, and limited adaptability. These upgrades could enable more stable and intelligent agents for use in research automation, software development, and business operations.
Historical Scaling Curve
To understand GPT-5’s likely leap, we need to track the scaling curve that began with GPT-3 — not just in terms of parameter counts, but also the shifts in training methodology, compute efficiency, and architectural innovations.
Each generation has brought more than just “more power”; it introduced entirely new design paradigms like instruction tuning, multi-modal integration, and mixture-of-experts routing. By analyzing this trend, we gain a realistic picture of what GPT-5 might deliver — and where the next inflection points in capability are likely to emerge.
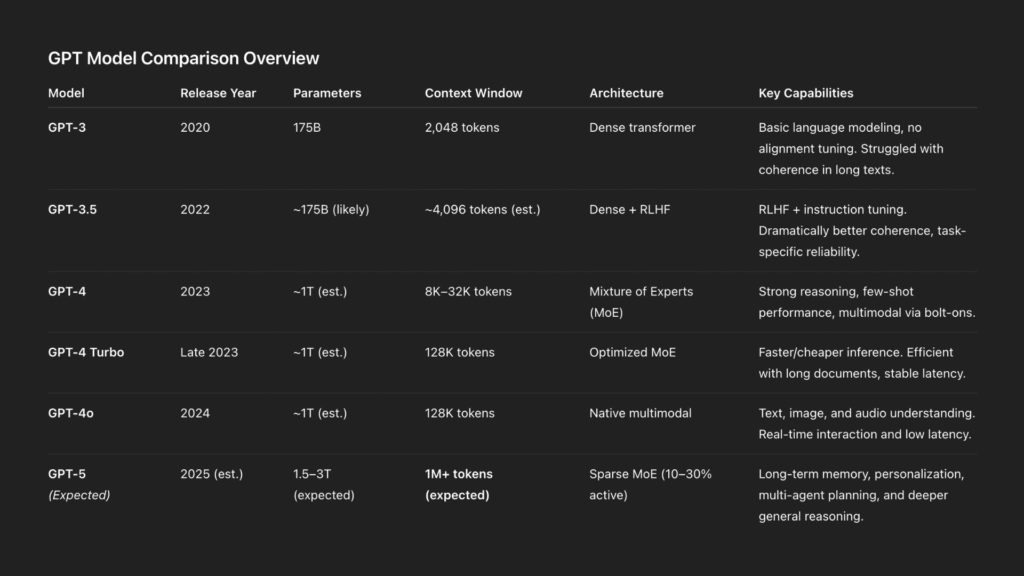
- GPT-3 (2020) – The model that started it all on a large scale, GPT-3 boasted 175 billion parameters and operated within a 2048-token context window. It was trained with approximately 3640 petaflop/s-days of compute on a dense, autoregressive transformer architecture. While revolutionary at the time, GPT-3 lacked task-specific alignment and struggled with coherence in long outputs.
- GPT-3.5 (2022) – Though its architecture likely remained at 175 billion parameters, GPT-3.5 introduced a dramatic leap in usability through reinforcement learning from human feedback (RLHF) and instruction fine-tuning. These updates made it significantly more coherent and reliable for real-world tasks, paving the way for ChatGPT’s initial mainstream adoption.
- GPT-4 (2023) – GPT-4 marked a radical departure in design philosophy. It’s rumoured to have scaled to 1.76 trillion parameters through a Mixture of Experts (MoE) architecture — where only a subset of model “experts” are activated per query. This enabled high performance without exponential inference costs. It expanded context capabilities from 8,192 to 32,768 tokens (depending on user access) and introduced multimodal capacity through add-on modules for vision and audio tasks.
Crucially, GPT‑4 delivered strong performance jumps: ~86.4% on MMLU, 95.3% on HellaSwag, 96.4% on ARC, and ~60–70% on TruthfulQA — placing it near the top of all AI models at the time. But GPT‑5 is expected to push further, likely exceeding 90–91% on MMLU, breaking previous barriers on HellaSwag and ARC, and achieving even higher consistency on TruthfulQA through better internal memory and fact-checking.
- GPT-4 Turbo / GPT-4o (2024) – Serving as a highly optimized variant, GPT-4 Turbo increased the context window dramatically to 128,000 tokens and offered faster, cheaper inference. GPT-4o then added native multimodal abilities, allowing the model to handle text, vision, and audio input simultaneously without requiring separate subsystems. It also brought noticeable improvements in response latency and real-time task handling.
- GPT‑4.5 (2025) – As an improved version of GPT‑4o, it maintains a 128K‑token context window, trained using new supervision techniques alongside SFT and RLHF, boosts world‑knowledge accuracy, and still relies on chain-of-thought via o1/o3 models but isn’t a full reasoning engine — showing it’s both powerful and a bridge to GPT‑5.
- GPT‑5 (Expected, 2025) – Building on GPT‑4’s foundation, GPT‑5 is expected to scale even further using the advanced Mixture of Experts (MoE) system — likely spanning 1.5 to 3 trillion parameters, while activating only 10–30% per query for high efficiency. Internally, it may route between dozens of expert subnetworks depending on task type, enabling smarter, context-aware performance. GPT‑5 is also rumored to support a context window exceeding 1 million tokens.
The result? A model not just bigger — but smarter per token, faster per inference, and more adaptable per user.
What This Could Mean for Real-World Use
Long-Term Adaptive AI Tutors
GPT‑5 could transform AI tutoring from session-based help into persistent, evolving mentorship — something GPT‑4 simply can’t do due to its shallow long-term personalization.
With user-specific memory, GPT‑5 can track a student’s development over weeks or months, remember past mistakes or misconceptions, and dynamically adjust its explanations, difficulty, and examples based on long-term learning patterns.Where GPT‑4 offers isolated tutoring, GPT‑5 may provide something closer to a private AI educator – one that teaches, evaluates, adapts, and remembers.
Solving Complex Technical Challenges
GPT‑5 could play a pivotal role in tackling high-complexity problems across software engineering, beyond just coding. As a software system architect, it may help design entire applications from scratch, suggest integration strategies, and read codebases (remembering 100K+ lines of code) to document them or find bugs and security flaws. This could enable solo developers to build what once required large teams.
Beyond engineering, GPT-5 might tackle unsolved problems or at least parts of them. It could be used to suggest approaches to complex equations, or explore mathematical conjectures.Google’s AlphaEvolve demonstrated AI can find new algorithms; a model like GPT-5 could similarly search for novel solutions in domains like cryptography, optimization, or physics simulations. It might not single-handedly solve a Clay Institute Millennium Prize problem, but it could become an invaluable assistant to those who do.
Personalized Worlds in Games
In entertainment, GPT‑5 could power NPCs with memory and adaptive behavior, making open-world games radically more dynamic. Each character could remember prior interactions, react to player behavior, evolve relationships, and generate unique quests, all in real time.
Combined with multimodal tools, developers could create entirely personalized story arcs, co-written with the player. It’s a leap toward AI-generated emergent storytelling, not just pre-scripted dialogue trees.
Medical Assistants
Doctors might use GPT‑5 as a diagnostic co-pilot. Input symptoms, lab results, and history — and it could generate a differential diagnosis, citing supporting cases from recent literature. With multi-modality, it could possibly analyze medical images (like MRI scans or x-rays) alongside textual reports, providing a holistic analysis – essentially a super-radiologist that also reads patient histories.
At the same time, GPT-5 could power health chatbots that triage patient concerns. For example, patients might describe their symptoms to a GPT-5 assistant which then advises whether they should seek urgent care, see a specialist, or try home care.
For routine follow-ups or chronic disease management, GPT-5 could check in with patients (via voice, in their local language) and record their progress, alerting human providers if something seems off. For doctors, this means less time spent on routine interactions — while patients get accessible, intelligent support at any hour.
Collaborative Research Engine
GPT‑5 could become a powerful assistant for anyone working with massive volumes of complex information — whether academic researchers or business analysts. In science, it might read and summarize thousands of papers, highlight relationships between findings, and even propose new hypotheses based on gaps in the literature. a biomedical researcher could ask, “Summarize all known findings on protein XYZ’s role in Alzheimer’s and suggest possible unexplored angles,” and get a thorough, sourced report.
In business, the same capabilities could be applied to financial statements, market research, or customer feedback. GPT‑5 could detect anomalies in quarterly reports, summarize key trends across millions of data points, or generate actionable recommendations, all while adjusting its insights to the specific context or goals of the user.
ChatGPT-5 Release Date
OpenAI CEO Sam Altman stated during a May 2025 episode of the official OpenAI podcast that GPT‑5 is expected to be released “later this summer.” While not a confirmed launch date, this timeline aligns with OpenAI’s typical release pattern of major models between June and August.
Additional supporting signals include:
- Several companies participating in early red team testing since early Q2 2025
- OpenAI job postings for prompt engineers and infrastructure experts referencing GPT-5-level capacity
- Backend updates to the OpenAI API system architecture consistent with model versioning preparations
Though OpenAI has not revealed the official release date, all taken into consideration, everything points to a late Q3 2025 public rollout.
GPT‑5 Pricing
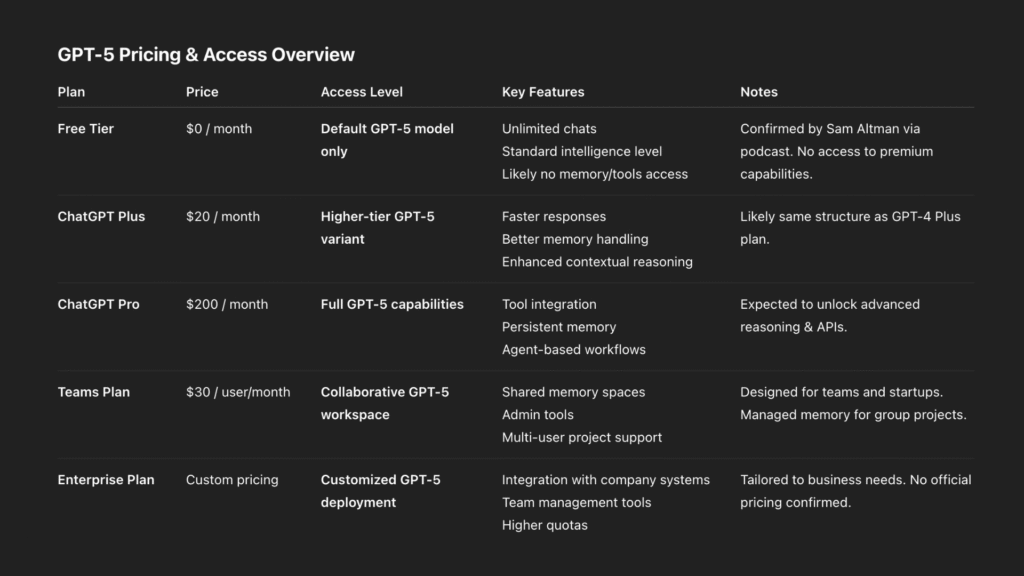
As GPT‑5 enters public deployment, OpenAI appears set to follow a tiered pricing strategy — keeping access flexible while reserving advanced capabilities for paying users. Here’s what we know so far:
Free Access
Sam Altman confirmed on a recent OpenAI podcast that GPT-5 will be available to free users. However, access will be limited to the default mode, which is expected to be a lower-performance variant.
Free users will get unlimited chats, but won’t have access to higher-level features like:
- persistent memory
- faster response times
- advanced reasoning tools
“We will be giving GPT-5 to free users, just on the default setting — the higher intelligence levels will be reserved for paid plans.” — paraphrased from Sam Altman, OpenAI Podcast
Paid Plans
OpenAI is expected to retain its current pricing tiers, offering more powerful GPT‑5 features to subscribers:
- ChatGPT Plus ($20/month):
Will likely grant access to higher-tier GPT‑5 versions, with better memory handling, faster responses, and superior contextual reasoning. - Pro ($200/month), Team ($30/user/month), Enterprise (flexible pricing) tiers: These are expected to unlock full GPT‑5 capabilities — including tool use, persistent memory, intelligent agents, and possibly integration with external systems (APIs, databases, proprietary tools).
Why Pricing May Stay the Same
Though GPT‑5 is more capable than its predecessors, OpenAI has strong reasons to keep pricing flat:
- Thanks to efficient model architectures (e.g. Mixture of Experts).
- OpenAI aims for broad adoption, which requires affordability — especially with growing competition from Anthropic (Claude) and Google (Gemini).
- A free tier with upsell potential helps bring more users into the ecosystem, improving feedback loops and fine-tuning data.
Final Thoughts
GPT‑5 will be more than a marginal upgrade — but perhaps not quite a revolution yet. Early signs point to five key advances: extended context windows, deeply integrated reasoning modules, native multimodal understanding, persistent user memory, and adaptive internal “thinking modes” that tune the model’s depth of reasoning on the fly.
Taken together, these features suggest that GPT‑5 could behave less like a reactive assistant and more like an evolving collaborator who is able to follow your projects across time, understand context-rich inputs like diagrams or videos, and even internalize your workflow preferences without repeated instruction.
At the same time, it’s important to stay grounded. What we’re seeing so far points to a smarter, more usable module – not necessarily a new paradigm. GPT‑5 appears to build upon GPT‑4’s core architecture with smart upgrades and a few additions. The breakthroughs may not always be flashy or obvious in a single prompt, but they may unlock new capabilities at the system and agent level over time.
And that may be the most important shift: GPT‑5 may be less about what it can do on its own, and more about what others can build with it. Its biggest impact may not be visible through typing in the chat, but through the autonomous agents, research pipelines, and developer tools it enables.
Whether GPT‑5 becomes a turning point — or just the next step forward — will depend not just on its intelligence, but on how it’s used. The potential is unmistakable. The real story starts now.




