
On 31 July 2026 DeepSeek shipped DeepSeek-V4-Flash-0731, the official release of V4-Flash that supersedes the April preview. It is the same architecture at the same price, $0.14 in / $0.28 out per million tokens, but the capability jump is large: DeepSeek’s own model card puts it at 82.7 on Terminal Bench 2.1, up from 61.8 for the preview, and above the far bigger V4-Pro preview at 72.1. Artificial Analysis moved it from 40 to 50 on its Intelligence Index, third in the open-weight field.
The V4 series first arrived on 24 April 2026 as previews, an open-source Mixture-of-Experts family with a native one-million-token context window. DeepSeek-V4-Pro has 1.6 trillion total parameters with 49 billion activated per token. DeepSeek-V4-Flash has 284 billion total with 13 billion activated. Both are on Hugging Face under the MIT License, through the DeepSeek API, and via chat.deepseek.com. This guide covers the architecture, the benchmark record and what the 0731 build changes.
DeepSeek is one of the headline names in open source AI, the category of models whose weights anyone can download, run, and fine-tune for free.
The headline claim is efficiency at extreme context length. At one million tokens, V4-Pro uses only 27% of the single-token inference FLOPs and 10% of the KV cache size of DeepSeek V3.2. V4-Flash pushes that further to 10% of the FLOPs and 7% of the cache. On Codeforces, V4-Pro reaches a 3,206 rating, ranking 23rd among human competitors, and on standard reasoning and agentic benchmarks it sits between GPT-5.2 and GPT-5.4. OpenAI’s GPT-5.5, released one day before V4 on April 23, pushes the closed frontier further out.
DeepSeek V4 sits near the top of our guide to the best open source AI models. On Artificial Analysis the open-weight order now runs Kimi K3 at 57, GLM-5.2 at 51 a V4-Flash-0731 at 50, with V4-Pro back at 44. GLM 5.2 is the flagship of Zhipu’s GLM family. V4 keeps a clear lead on long context, where nothing else open runs a million tokens this cheaply.
For anyone running Fello AI on Mac, iPhone, or iPad, DeepSeek V4 sits alongside ChatGPT, Claude, Gemini, Kimi and Perplexity in a single app for $9.99/month, with 25,000+ five-star reviews and no extra subscriptions per model.
The Key Takeaways
- DeepSeek-V4-Flash-0731 shipped on 31 July 2026 and replaced the April preview. Same 284B/13B architecture, same price, much stronger agentic performance.
- Terminal Bench 2.1 went from 61.8 to 82.7 on DeepSeek’s own harness, past the V4-Pro preview at 72.1. Artificial Analysis, running its own harness, scores it lower at 78.7.
- $0.14 / $0.28 per million tokens, which works out to $0.03 per Intelligence Index task, the cheapest figure on the Artificial Analysis board. Gemini 3.6 Flash scores the same 50 and costs $0.56.
- Both models are MIT licensed with a native 1M token context and up to 384K tokens of output. V4-Pro is still a preview.
- The DSpark speculative-decoding module now ships inside the checkpoint, enabled with one flag in vLLM or SGLang.
What Is DeepSeek V4
DeepSeek V4 is the fourth generation flagship model family from DeepSeek, the Hangzhou based AI lab that rocked global markets in January 2025 with the low-cost R1 reasoning model. V4 replaced DeepSeek V3 and V3.2, which were retired after 24 July 2026. For DeepSeek’s next reasoning model, R2, we track the rumours and release timing separately.
V4-Flash is no longer a preview. The 0731 build is the official release, and DeepSeek describes it as carrying “substantially enhanced agentic capabilities” over the preview it replaces. V4-Pro is still labelled a preview. DeepSeek describes V4 as the first open model family built from the ground up around million-token contexts as a default, rather than a bolt-on feature. The tech report frames this as breaking “the efficiency barrier of ultra-long-context processing” and positions long context as the next axis of test-time scaling, after the reasoning-model wave that R1, o1, and their successors opened.
Both V4 models are open source, published under the DeepSeek collection on Hugging Face. Developers can download the weights, run them locally, and fine-tune them. The API is live today at api-docs.deepseek.com, and supports both the OpenAI ChatCompletions and Anthropic API formats.
Two Models in the V4 Series
DeepSeek V4 ships in two sizes, both Mixture-of-Experts.
| Model | Total Params | Active Params | Layers | Hidden Size | Routed Experts | Active Experts | Training Tokens |
|---|---|---|---|---|---|---|---|
| DeepSeek-V4-Flash | 284B | 13B | 43 | 4,096 | 256 | 6 | 32T |
| DeepSeek-V4-Pro | 1.6T | 49B | 61 | 7,168 | 384 | 6 | 33T |
Each model has one shared expert plus the routed experts listed above. The first three MoE layers use Hash routing, which assigns experts by a fixed hash of the token ID, while the rest use the standard DeepSeekMoE learned routing. Both models have Multi-Token Prediction enabled with depth 1, the same MTP strategy used in V3.
V4-Flash is positioned as the cost-effective default for most serving. V4-Pro is the frontier model, aimed at tasks where maximum intelligence matters more than price per token. Both support the same 1M context and same agentic capabilities, and both offer Thinking and Non-Thinking modes.
The Big Architectural Bet
The biggest change in V4 is the attention stack. The DeepSeek team argues that the quadratic cost of standard attention is now the binding constraint on further progress, especially as models run longer agentic loops and chew through bigger document sets. V4 reshapes attention to attack that cost.
Three architectural changes carry the release:
- A hybrid attention mechanism combining Compressed Sparse Attention (CSA) a Heavily Compressed Attention (HCA).
- Manifold-Constrained Hyper-Connections (mHC), an upgrade to residual connections designed for numerical stability in deep stacks.
- A switch to the Muon optimizer (from AdamW for most parameters), which DeepSeek reports gives faster convergence and more stable training at trillion-parameter scale.
Other details inherited from V3 include DeepSeekMoE with fine-grained routed and shared experts, FP8 precision for most weights, Multi-Token Prediction, and the 128K vocabulary tokenizer. The routed expert weights are now stored in FP4, which halves memory versus FP8 and opens the door to further efficiency gains on hardware that exposes faster FP4 math.
Hybrid CSA and HCA Attention
Standard transformer attention looks at every past token for every new token. At one million tokens this is untenable, both in FLOPs and in KV cache size. V4 splits the problem into two complementary passes.
Compressed Sparse Attention (CSA) first compresses KV caches along the sequence dimension (with compression rate 4 in V4), then applies DeepSeek Sparse Attention, which was introduced in V3.2. A lightning indexer picks the top-k most relevant compressed KV entries for each query. V4-Pro selects the top 1,024, V4-Flash selects the top 512. A short sliding window of 128 tokens is added on the side so local context is never missed.
Heavily Compressed Attention (HCA) applies a much more aggressive compression rate of 128 but then performs dense attention over that compressed representation. This gives the model a cheap, global view of distant tokens in every layer.
CSA and HCA layers are interleaved through the network. The first two layers of V4-Flash use pure sliding window attention, while V4-Pro starts with HCA layers. The result is that the model can route between precise sparse lookups (CSA) and broad compressed context (HCA) at every depth, rather than picking one strategy up front.
Training Data, Compute, and Optimizer
V4-Flash was pre-trained on 32 trillion tokens. V4-Pro was pre-trained on 33 trillion. Both used a batch size schedule that ramps up to a maximum of 75.5 million tokens for Flash and 94.4 million tokens for Pro, then holds there for most of training.
Training sequence length was extended in stages: 4K, then 16K, 64K, and finally 1M. Dense attention ran for the first 1T tokens (longer for Pro), after which sparse attention was introduced at 64K sequence length and kept for the rest of training. The lightning indexer was warmed up in a short interim stage before full CSA training kicked in.
The team switched to Muon for most parameters, with AdamW kept only for embeddings, the prediction head, and RMSNorm weights. Peak learning rate was 2.7e-4 for Flash and 2.0e-4 for Pro, decayed by a cosine schedule in the final stretch.
FP4 quantization-aware training was applied to MoE expert weights and the indexer QK path. DeepSeek also reports two new stability techniques that materially cut loss spikes at trillion-parameter scale:
- Anticipatory Routing decouples backbone and router updates, using current weights for features but historical weights for routing indices, activated automatically when a spike is detected.
- SwiGLU Clamping bounds the linear and gate components of SwiGLU to stabilize activations.
Post-Training with On-Policy Distillation
The post-training pipeline is where V4 most clearly diverges from V3. Instead of running one large mixed Reinforcement Learning stage over a generalist model, DeepSeek trains a separate specialist expert for each domain (math, coding, agent tasks, instruction following, and so on). Each expert goes through Supervised Fine-Tuning on high-quality domain data, followed by Group Relative Policy Optimization (GRPO) RL with domain-specific reward models.
The unified final model is then trained by On-Policy Distillation (OPD), where it acts as a student optimizing the reverse KL loss against the set of specialist teachers. This is the step that rolls all the domain expertise into one coherent model. It is the same recipe that Kimi K2.6 and several other recent open models have converged on, and it is one reason open models have narrowed the gap with closed frontier systems on specialist benchmarks.
DeepSeek also built out a sandbox infrastructure for agentic RL, a preemptible fault-tolerant rollout service, and a scaled RL framework that can run episodes on million-token contexts. These are the kinds of investments that are invisible in benchmark tables but that gate whether long-horizon agent work is actually trainable at scale.
Benchmark Results
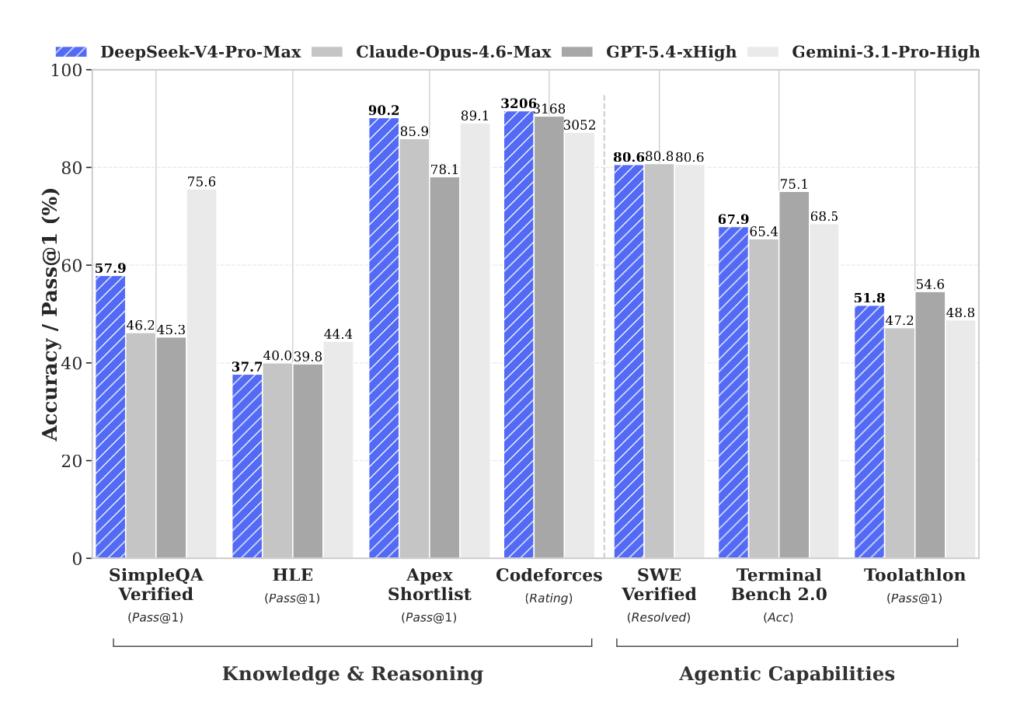
The DeepSeek tech report publishes head-to-head numbers for DeepSeek-V4-Pro-Max against Claude Opus 4.6-Max, GPT-5.4-xHigh, Gemini-3.1-Pro-High, and the leading open models Kimi K2.6-Thinking and GLM-5.1-Thinking, since updated by GLM 5.2. The table below pulls the full row set.
| Benchmark | Opus 4.6 Max | GPT-5.4 xHigh | Gemini 3.1 Pro High | Kimi K2.6 | GLM-5.1 | DeepSeek V4-Pro-Max |
|---|---|---|---|---|---|---|
| MMLU-Pro | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
| SimpleQA-Verified | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
| Chinese-SimpleQA | 76.4 | 76.8 | 85.9 | 75.9 | 75.0 | 84.4 |
| GPQA Diamond | 91.3 | 93.0 | 94.3 | 90.5 | 86.2 | 90.1 |
| HLE (no tools) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
| LiveCodeBench | 88.8 | – | 91.7 | 89.6 | – | 93.5 |
| Codeforces (rating) | – | 3,168 | 3,052 | – | – | 3,206 |
| HMMT 2026 Feb | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
| IMOAnswerBench | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
| Apex | 34.5 | 54.1 | 60.9 | 24.0 | 11.5 | 38.3 |
| Apex Shortlist | 85.9 | 78.1 | 89.1 | 75.5 | 72.4 | 90.2 |
| MRCR 1M | 92.9 | – | 76.3 | – | – | 83.5 |
| CorpusQA 1M | 71.7 | – | 53.8 | – | – | 62.0 |
| Terminal Bench 2.0 | 65.4 | 75.1 | 68.5 | 66.7 | 63.5 | 67.9 |
| SWE Verified | 80.8 | – | 80.6 | 80.2 | – | 80.6 |
| SWE Pro | 57.3 | 57.7 | 54.2 | 58.6 | 58.4 | 55.4 |
| SWE Multilingual | 77.5 | – | – | 76.7 | 73.3 | 76.2 |
| BrowseComp | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
| HLE with tools | 53.1 | 52.0 | 51.6 | 54.0 | 50.4 | 48.2 |
| GDPval-AA (Elo) | 1,619 | 1,674 | 1,314 | 1,482 | 1,535 | 1,554 |
| MCPAtlas Public | 73.8 | 67.2 | 69.2 | 66.6 | 71.8 | 73.6 |
| Toolathlon | 47.2 | 54.6 | 48.8 | 50.0 | 40.7 | 51.8 |
A few things jump out.
V4-Pro-Max sets a new state of the art for open models on SimpleQA-Verified with 57.9%, a 20 point jump over the best previous open model. It wins outright on LiveCodeBench (93.5%), Codeforces rating (3,206), Apex Shortlist (90.2%), and Toolathlon (51.8%). On Codeforces in particular, 3,206 puts the model at 23rd among human competitors, which is the first time an open model has matched a closed frontier model on competitive programming.
The gap to proprietary frontier models has narrowed but not closed. Gemini 3.1 Pro still leads on general knowledge (MMLU-Pro, SimpleQA, GPQA Diamond, HLE, Chinese-SimpleQA), GPT-5.4 leads on agentic coding (Terminal Bench 2.0 at 75.1% vs V4-Pro at 67.9%), and Claude Opus 4.6 leads on long-context retrieval (MRCR 1M at 92.9% vs 83.5%) and on the GDPval Elo ranking for economically valuable work.
DeepSeek describes this positioning directly in the paper: V4-Pro-Max is “marginally short of GPT-5.4 and Gemini-3.1-Pro” on reasoning, placing it about three to six months behind the frontier. For an open-weight model available for free download, that is a meaningful shift from where R1 left things a year ago.
How V4-Pro-Max Compares to Opus 4.6, GPT-5.4, Gemini 3.1 Pro
Reading across the benchmark table, three patterns stand out.
Against Claude Opus 4.6, V4-Pro-Max wins on LiveCodeBench (93.5 vs 88.8), Codeforces (3,206 vs untested), IMOAnswerBench (89.8 vs 75.3), Apex Shortlist (90.2 vs 85.9), and Toolathlon (51.8 vs 47.2). Opus leads on knowledge (MMLU-Pro, GPQA Diamond, HLE), long-context retrieval on MRCR and CorpusQA, SWE Multilingual, and GDPval-AA. The read is that V4 is the stronger picker for competitive programming and tool use, while Opus 4.6 is still the stronger picker for knowledge work and very long documents. Note that Anthropic has since released Opus 4.7 and the restricted Claude Mythos Preview, both of which sit above Opus 4.6 on these benchmarks.
Against GPT-5.4, V4-Pro-Max edges ahead on LiveCodeBench, Codeforces, Apex Shortlist, MCPAtlas, and Toolathlon. GPT-5.4 wins HMMT, Apex, GDPval-AA, and Terminal Bench 2.0 by a wide margin (75.1 vs 67.9). OpenAI has since released GPT-5.5 at 82.7% on Terminal Bench 2.0, which re-opens the gap on agentic coding.
Against Gemini 3.1 Pro, V4-Pro-Max wins LiveCodeBench, Codeforces, IMOAnswerBench, Apex Shortlist, CorpusQA 1M, and Toolathlon, and nearly ties on most others. Gemini holds its clearest advantages on general world knowledge (SimpleQA-Verified 75.6, MMLU-Pro 91.0, GPQA Diamond 94.3).
Agentic Coding and Tool Use
DeepSeek has leaned hard into agentic coding as a deployment story. The team explicitly notes that V4 is “seamlessly integrated with leading AI agents like Claude Code, OpenClaw, and OpenCode,” and says V4 is already powering its own internal agentic coding. Alibaba followed the same playbook in May with Qwen3.7-Max, which supports the Anthropic API protocol natively and demonstrated a 35-hour autonomous coding run at launch. A sample PDF in the announcement was generated end to end by V4-Pro.
On agentic benchmarks, V4-Pro-Max posts 80.6% on SWE-Bench Verified, 55.4% on SWE-Bench Pro, 76.2% on SWE Multilingual, 67.9% on Terminal Bench 2.0, 73.6% on MCPAtlas, and 51.8% on Toolathlon. The MCPAtlas and Toolathlon numbers matter because those benchmarks evaluate a wide range of external tools and MCP services, so a strong score indicates the model generalizes beyond whatever internal agent harness DeepSeek used during RL.
Those figures are from the April preview, and the 0731 build turned that conclusion around. In the preview, V4-Flash-Max was clearly the weaker agent, dropping from V4-Pro’s 67.9% to 56.9% on Terminal Bench 2.0. On the official release, DeepSeek’s own card puts V4-Flash-0731 at 82.7 on Terminal Bench 2.1 against the V4-Pro preview’s 72.1, with matching gains on NL2Repo (54.2 vs 38.5), Cybergym (76.7 vs 52.7) and DeepSWE (54.4 vs 12.8). DeepSeek frames this as beating Pro “despite its far smaller activated parameter count”.
So the practical advice has flipped. Start with V4-Flash for agent work, not just for chat, and reach for V4-Pro only where raw knowledge depth matters. One caveat on those numbers: they come from DeepSeek’s own harness at max reasoning effort. Artificial Analysis, running its own, scores V4-Flash-0731 at 78.7 on the same benchmark. Both are real results from different setups, so treat 82.7 as the vendor figure rather than a neutral one.
DeepSeek reports that in internal evaluation, V4-Pro-Max “outperforms Claude Sonnet 4.5 and approaches the level of Opus 4.5” on agent tasks. Public-benchmark gaps to newer closed models remain, but the internal number hints that the gap on real workloads is smaller than the headline scores suggest.
Mathematical Reasoning
Formal math is one place V4 clearly stretches past the field. On Putnam-200 Pass@8 with minimal tools (the setup introduced by Seed-Prover), V4-Flash-Max scores 81.0, compared to 35.5 for Seed-2.0-Pro, 26.5 for Gemini-3-Pro, and 26.5 for Seed-1.5-Prover.
On the frontier Putnam-2025 setup, which combines informal reasoning with formal verification and heavier compute, V4 reaches a proof-perfect 120/120, tying Axiom and ahead of Aristotle (100/120) and Seed-1.5-Prover (110/120).
On competition math benchmarks, HMMT 2026 February at 95.2 and IMOAnswerBench at 89.8 put V4-Pro-Max within range of GPT-5.4 (97.7 and 91.4) and ahead of Gemini 3.1 Pro on IMOAnswerBench.
One Million Token Context in Practice
Both V4 models support 1M-token context natively. This is the default, not a special long-context tier, and it comes without a long-context price premium.
On MRCR, an in-context retrieval benchmark, V4-Pro holds 94% retrieval accuracy up to 128K tokens and 82% at 512K tokens, still landing at 66% at 1M tokens. DeepSeek reports that V4-Pro “outperforms Gemini-3.1-Pro on the MRCR task” (83.5 vs 76.3) but “remains behind Claude Opus 4.6” (92.9).
On CorpusQA, a benchmark closer to real long-document use, V4-Pro reaches 62.0% at 1M tokens, beating Gemini 3.1 Pro at 53.8%. The takeaway is that for long document QA, V4-Pro is genuinely competitive with the closed long-context leaders, and clearly ahead of the previous open-source field.
The tech report frames long context as the next scaling axis, opening the door to longer agentic runs, more involved cross-document analysis, and exploratory paradigms like online learning. None of that is possible if inference at 1M tokens is too expensive to run, which is where the architectural efficiency gains come in.
Efficiency and KV Cache Savings
The headline efficiency numbers, as reported in the tech report, at a 1M-token context:
| Model | FLOPs vs V3.2 | KV Cache vs V3.2 |
|---|---|---|
| DeepSeek-V4-Pro | 27% (3.7x lower) | 10% (9.5x smaller) |
| DeepSeek-V4-Flash | 10% (9.8x lower) | 7% (13.7x smaller) |
Those numbers are what make 1M contexts economically feasible. A 10x smaller KV cache means a single GPU can serve roughly 10x as many concurrent long-context sessions, which directly changes the price sheet for agentic and research workloads.
The gains come from three sources: sparse attention via CSA, heavy compression via HCA, and FP4 storage for MoE expert weights. On future hardware that exposes faster FP4 math, DeepSeek estimates another third of efficiency on top of today’s numbers.
Reasoning Effort Modes
Each V4 model exposes three reasoning effort levels: Non-Think, High, and Max. Max uses longer contexts and reduced length penalties in RL, and is the mode that should be used for the hardest reasoning tasks.
| Benchmark | Flash Non-Think | Flash High | Flash Max | Pro Non-Think | Pro High | Pro Max |
|---|---|---|---|---|---|---|
| MMLU-Pro | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
| SimpleQA-Verified | 23.1 | 28.9 | 34.1 | 45.0 | 46.2 | 57.9 |
| GPQA Diamond | 71.2 | 87.4 | 88.1 | 72.9 | 89.1 | 90.1 |
| HLE | 8.1 | 29.4 | 34.8 | 7.7 | 34.5 | 37.7 |
| LiveCodeBench | 55.2 | 88.4 | 91.6 | 56.8 | 89.8 | 93.5 |
| HMMT 2026 Feb | 40.8 | 91.9 | 94.8 | 31.7 | 94.0 | 95.2 |
| Terminal Bench 2.0 | 49.1 | 56.6 | 56.9 | 59.1 | 63.3 | 67.9 |
| SWE Verified | 73.7 | 78.6 | 79.0 | 73.6 | 79.4 | 80.6 |
| MRCR 1M | 37.5 | 76.9 | 78.7 | 44.7 | 83.3 | 83.5 |
Two observations. First, reasoning modes matter far more than raw size for hard reasoning tasks: HLE goes from 7.7 (Pro Non-Think) to 37.7 (Pro Max), a near 5x jump. Second, Flash Max is surprisingly close to Pro on reasoning benchmarks when given enough thinking budget, which is why DeepSeek calls Flash “a highly cost-effective architecture for complex reasoning tasks.” For knowledge tasks where parameter count matters, Pro holds a clear edge.
Huawei Ascend Support and Chinese Hardware
Alongside the V4 release, Huawei announced that its Ascend supernode, powered by the new Ascend 950 AI chips, will fully support DeepSeek V4 out of the box. This is a notable signal, because it means V4 is immediately deployable on Chinese domestic AI hardware at scale, without dependency on US-manufactured GPUs that are subject to export restrictions.
The pairing reflects a broader push by Chinese AI infrastructure to build a self-contained stack: Chinese weights, Chinese chips, Chinese inference software. For enterprises and research groups operating inside mainland China, this likely matters more than any single benchmark number.
Pricing and API
DeepSeek V4 has been on the DeepSeek API since 24 April 2026. API users do not need to change their base_url, only the model parameter, and deepseek-v4-flash now serves the 0731 build with no call-site change at all:
deepseek-v4-profor V4-Prodeepseek-v4-flashfor V4-Flash
Both models support the OpenAI ChatCompletions format and the Anthropic API format. Both expose 1M context and dual Thinking and Non-Thinking modes, configured via the thinking mode parameter.
Final prices are published. V4-Flash costs $0.14 per million input tokens on a cache miss, $0.0028 on a cache hit, and $0.28 per million output tokens. V4-Pro costs $0.435 / $0.003625 / $0.87 on the same three lines. Both carry the full 1M context at no premium and cap output at 384K tokens. Flash allows 2,500 concurrent requests against Pro’s 500.
🔴 The old endpoints are gone. deepseek-chat a deepseek-reasoner were retired after 24 July 2026, 15:59 UTC, and DeepSeek’s docs now list exactly two model IDs. If either string is still in a config file somewhere, those calls fail. DeepSeek has also said it will move to peak and off-peak pricing, at 2x the regular rate during peak hours, but has not announced a date.
Availability and Migration from V3
V4 is available in three ways today.
chat.deepseek.com. The web chatbot exposes V4 through two toggles, Expert Mode and Instant Mode, mapping to V4-Pro-Max and V4-Flash style fast responses. No new account is needed if you already use DeepSeek Chat.
DeepSeek API. Available via deepseek-v4-pro a deepseek-v4-flash. Both models default to 1M context. Thinking and Non-Thinking modes are selectable per request.
Hugging Face. Open weights are published at huggingface.co/collections/deepseek-ai/deepseek-v4. The full technical report is available as a PDF in the V4-Pro repository. Inference requires serious hardware for V4-Pro (tens of GPUs for any reasonable throughput), but V4-Flash with 13B active parameters is well within reach of a well-equipped single-server deployment.
Migration from V3 is largely drop-in. The tokenizer is compatible (still 128K vocabulary, same special tokens plus a few new ones for context construction). The thinking-mode API surface is unchanged. The main change is the new 1M default context and the new model IDs.
Limitations
DeepSeek is unusually candid in the tech report about V4’s remaining limitations.
Architecture complexity. To minimize risk on the biggest architectural changes (mHC, hybrid CSA and HCA, Muon, FP4), V4 retained many previously validated V3 components. DeepSeek describes the resulting architecture as “relatively complex” and says future versions will try to “distill the architecture down to its most essential designs.”
Training stability. Anticipatory Routing and SwiGLU Clamping worked in practice but the team admits their “underlying principles remain insufficiently understood” and calls out training stability as an active area for foundational research.
Knowledge gap. V4-Pro-Max trails Gemini 3.1 Pro on most knowledge-heavy benchmarks (MMLU-Pro, SimpleQA, GPQA Diamond, HLE). The gap has narrowed substantially but has not closed.
Long-context retrieval ceiling. Above 128K tokens, retrieval accuracy starts to degrade, dropping to 66% on MRCR at 1M tokens. This is still better than most open models and Gemini 3.1 Pro, but it is not the near-perfect recall some benchmarks have reported for Claude Opus 4.6.
Frontier agent tasks. On the April preview numbers, V4-Pro-Max trailed the closed frontier on Terminal Bench 2.0 (67.9) and SWE Pro (55.4). The 0731 build narrowed that considerably on the agent side, but the current closed flagships still lead on the hardest agentic coding work. Both have moved on since this table was published, to OpenAI’s GPT-5.6 line a Claude Opus 5.
Multimodal. V4 is text only. DeepSeek says it is “working on incorporating multimodal capabilities to our models” but the current release does not accept images, audio, or video.
What This Means for You
For developers. V4-Flash is the default for high-volume serving now that deepseek-chat a deepseek-reasoner are retired. With 13B active parameters, a million-token context and the 0731 agentic gains, it is the cheapest way to buy a given amount of measured capability anywhere on the Artificial Analysis board, at $0.03 per index task. Worth knowing before you standardise on it: that score is one board old and V4-Flash has no human-preference votes on any Arena leaderboard yet. V4-Pro is worth a direct swap in for Claude Opus on competitive coding, tool-heavy agent workflows, and any task that benefits from long context.
For open-source and self-hosted deployments. V4 is the strongest open model family today on competitive programming and formal math, and the first open model to match frontier closed systems on Codeforces. It is also the first widely deployable open model built natively for million-token contexts. For any team standing up its own LLM stack, V4 materially resets the build vs buy calculus.
For agent builders. The CSA/HCA efficiency gains are what turn 1M-token agentic loops from research demos into production-viable workloads. Token efficiency at long context directly compounds into lower cost per task and longer agent runs per dollar.
For everyday users. If you just want to use all the frontier models without juggling many subscriptions, Fello AI bundles DeepSeek with ChatGPT, Claude, Gemini, Grok and Perplexity in one native Mac, iPhone and iPad app for $9.99/month, with 25,000+ five-star reviews.
V4 is the clearest evidence yet that open models have closed most of the gap to the closed-source frontier, while pushing a real architectural lead on long-context efficiency. The next question is no longer whether open models can compete at the frontier. It is what becomes possible once million-token contexts are routine, and V4 is the first release built to answer that.
FAQ
What is DeepSeek-V4-Flash-0731?
It is the official release of DeepSeek V4-Flash, published on 31 July 2026, which supersedes the April preview. It keeps the same 284B total / 13B active architecture, the same 1M context and the same $0.14/$0.28 price, and adds what DeepSeek calls substantially enhanced agentic capabilities. Calling deepseek-v4-flash gets you the 0731 build automatically.
Is DeepSeek V4 free?
The weights are. Both V4 models are published on Hugging Face under the MIT License, so you can download, run and fine-tune them at no cost if you have the hardware. The chat at chat.deepseek.com is free for individuals, and the API is pay-per-token. See our DeepSeek pricing guide for the full breakdown.
Is V4-Flash or V4-Pro better for agent work?
V4-Flash, since the 0731 build. DeepSeek’s own model card puts V4-Flash-0731 at 82.7 on Terminal Bench 2.1 against the V4-Pro preview’s 72.1, and it wins on NL2Repo, Cybergym and DeepSWE too, at roughly a third of Pro’s price. V4-Pro still leads on knowledge-heavy work.
How much does the DeepSeek V4 API cost?
V4-Flash is $0.14 per million input tokens on a cache miss, $0.0028 on a cache hit and $0.28 per million output tokens. V4-Pro is $0.435 / $0.003625 / $0.87. The full 1M context carries no price premium on either model.
Can DeepSeek V4 handle images or audio?
No. V4 is text only. DeepSeek says it is “working on incorporating multimodal capabilities to our models”, but neither V4-Flash nor V4-Pro accepts images, audio or video today.




