
On April 16, 2026, Anthropic released Claude Opus 4.7, its most capable generally available model to date. The update brings a 13% lift on coding benchmarks, 3x more production tasks resolved, high-resolution vision support up to 3.75 megapixels, and a new tokenizer. Pricing stays the same as Opus 4.6 at $5/$25 per million tokens.
At launch, Claude Opus 4.7 shipped across the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry, replacing Opus 4.6 as the default Opus model.
Opus 4.7 has since been superseded twice over. Anthropic shipped Opus 4.8, then Claude Opus 5 on July 24, 2026, which now tops the Artificial Analysis Intelligence Index at 61 at the same $5/$25 per million tokens. Read this as the record of what 4.7 changed, and see our full Claude Opus 5 breakdown for the current flagship.
What Changed in Opus 4.7
Opus 4.7 is not a new model tier. It is a direct upgrade to Opus 4.6, continuing Anthropic’s roughly two-month release cadence (Opus 4.5 in November 2025, Opus 4.6 in February 2026, now Opus 4.7 in April 2026).
The biggest improvements are in software engineering, vision, instruction following, and sustained reasoning over long agentic runs. Anthropic describes the model as “highly autonomous” and “exceptionally well on long-horizon agentic work, knowledge work, vision tasks, and memory tasks.”
Here’s a quick summary of what’s new:
- 13% coding lift on a 93-task benchmark
- 3x more production tasks resolved on Rakuten-SWE-Bench
- High-res vision up to 2,576 pixels (3.75 megapixels), triple the previous limit
- New
xhigheffort level betweenhighandmax - Task budgets in public beta for API users
- Updated tokenizer with improved performance (but 1.0 to 1.35x more tokens)
- Stricter instruction following (prompts may need retuning)
- Better file-system memory across multi-session work
- Cybersecurity safeguards that detect and block high-risk requests
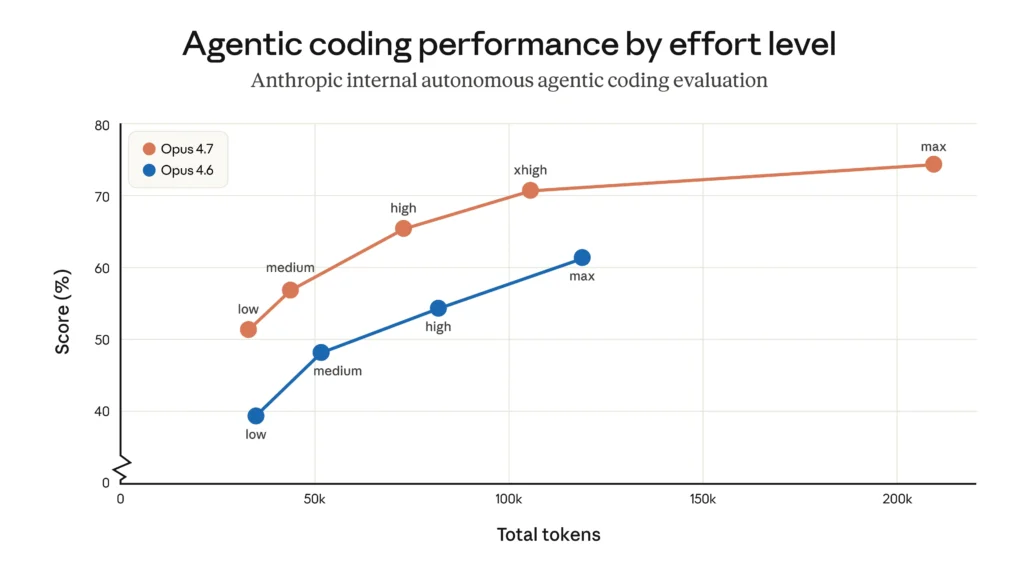
Benchmark Results
Anthropic published detailed benchmark numbers. Opus 4.7 outperforms Opus 4.6 across coding, vision, document reasoning, and knowledge work tasks. According to Anthropic and third-party reports, it outperformed GPT-5.4 and Gemini 3.1 Pro on agentic coding and computer use tasks at launch. OpenAI’s response came one week later with GPT-5.5 on April 23, 2026, and the picture now splits: Opus 4.7 still leads SWE-bench Pro at 64.3% vs GPT-5.5’s 58.6% for multi-file coding, while GPT-5.5 pulls ahead on Terminal-Bench 2.0 (82.7% vs 69.4%) and OSWorld-Verified (78.7% vs 78.0%) for agentic computer-use work. For where this leaves the two companies on revenue, valuation, and enterprise share, see our Anthropic vs OpenAI breakdown.
| Benchmark | Improvement over Opus 4.6 |
|---|---|
| 93-task coding benchmark | 13% lift |
| Rakuten-SWE-Bench (production tasks) | 3x more resolved |
| Complex workflow task success | 10-15% improvement |
| OfficeQA Pro (document reasoning) | 21% fewer errors |
| Visual acuity (computer use) | 98.5% vs 54.5% |
| Multi-step workflows | 14% improvement, one-third fewer tool errors |
Opus 4.7 also achieved state-of-the-art results on GDPval-AA, a benchmark that measures economically valuable knowledge work in finance and legal domains.
The model still ranks below Claude Mythos Preview, Anthropic’s most powerful model, which remains restricted to Project Glasswing partners and is not generally available.
High Resolution Vision Support
This is the first Claude model with high-resolution image support. Maximum image resolution jumped from 1,568 pixels on the long edge (about 1.15 megapixels) to 2,576 pixels (about 3.75 megapixels). That’s roughly 3x the visual capacity of previous Claude models.
The practical benefits include better performance on:
- Computer use and screenshot understanding. The model’s coordinates now map 1:1 with actual pixels, eliminating the scale-factor math that was previously required.
- Document analysis. Higher resolution means the model can read smaller text and finer details in scanned documents, slides, and diagrams.
- Low-level perception. Improved pointing, measuring, counting, and similar precision tasks.
- Image localization. Better bounding-box detection in natural images.
Higher resolution means more tokens per image. If the extra fidelity is not needed, Anthropic recommends downsampling images before sending them to avoid unnecessary token costs.
New Effort Level and Task Budgets
Opus 4.7 adds xhigh, a new effort level that sits between high and max. Anthropic recommends starting with xhigh for coding and agentic use cases and using at least high for most intelligence-sensitive tasks.
The effort parameter lets you trade capability for speed and cost. Lower effort means faster, cheaper responses. Higher effort means more thorough reasoning and more tool calls.
Task budgets are a new feature in public beta. A task budget gives the model a rough token target for an entire agentic loop (thinking, tool calls, tool results, and final output). The model sees a running countdown and uses it to prioritize work and wrap up gracefully as the budget runs out.
Task budgets are advisory, not hard caps. They are distinct from max_tokens, which is a hard per-request ceiling the model is not aware of. The minimum task budget is 20,000 tokens. For open-ended agentic tasks where quality matters more than speed, Anthropic recommends not setting a task budget at all.
API Breaking Changes
Opus 4.7 introduces several breaking changes to the Messages API. If you use Claude Managed Agents, there are no breaking API changes.
Extended thinking budgets removed. Setting thinking: {"type": "enabled", "budget_tokens": N} now returns a 400 error. Adaptive thinking is the only supported thinking mode. To enable it, set thinking: {"type": "adaptive"} explicitly. It is off by default.
Sampling parameters removed. Setting temperature, top_p, or top_k to any non-default value returns a 400 error. The recommended migration is to omit these parameters entirely and use prompting to guide the model’s behavior.
Thinking content omitted by default. Thinking blocks still appear in the response stream, but their content is empty unless you opt in with "display": "summarized". If your product streams reasoning to users, the new default will look like a long pause before output begins.
Updated Tokenizer
Opus 4.7 uses a new tokenizer that contributes to its improved performance across tasks. The tradeoff is that the same input text may produce 1.0x to 1.35x more tokens compared to Opus 4.6. The exact increase varies by content type.
The 1M token context window remains available at standard API pricing with no long-context premium. Anthropic recommends updating max_tokens parameters to give additional headroom, including compaction triggers.
Behavior Changes Worth Noting
These are not API-breaking, but they may require prompt updates if you are migrating from Opus 4.6:
- More literal instruction following. The model will not silently generalize an instruction from one item to another or infer requests you didn’t make. This is especially noticeable at lower effort levels.
- Response length adapts to task complexity rather than defaulting to a fixed verbosity.
- Fewer tool calls by default. The model uses reasoning more and tools less. Raising effort increases tool usage.
- More direct, opinionated tone. Less validation-forward phrasing and fewer emoji than Opus 4.6’s warmer style.
- More regular progress updates during long agentic traces. If you added scaffolding to force interim status messages, try removing it.
- Fewer subagents spawned by default. Can be steered through prompting.
Memory and Knowledge Work
Opus 4.7 is better at writing and using file-system-based memory. If an AI agent maintains a scratchpad, notes file, or structured memory store across turns, it should be better at jotting down notes and leveraging them in future tasks.
The model also shows meaningful gains on knowledge work, particularly tasks where it needs to visually verify its own outputs:
- Document editing. Better at producing and self-checking tracked changes in .docx files and slide layouts in .pptx files.
- Charts and figures. Better at programmatic tool calling with image-processing libraries to analyze charts, including pixel-level data transcription.
Anthropic notes the model is “more tasteful and creative when completing professional tasks, producing higher-quality interfaces, slides, and docs.”
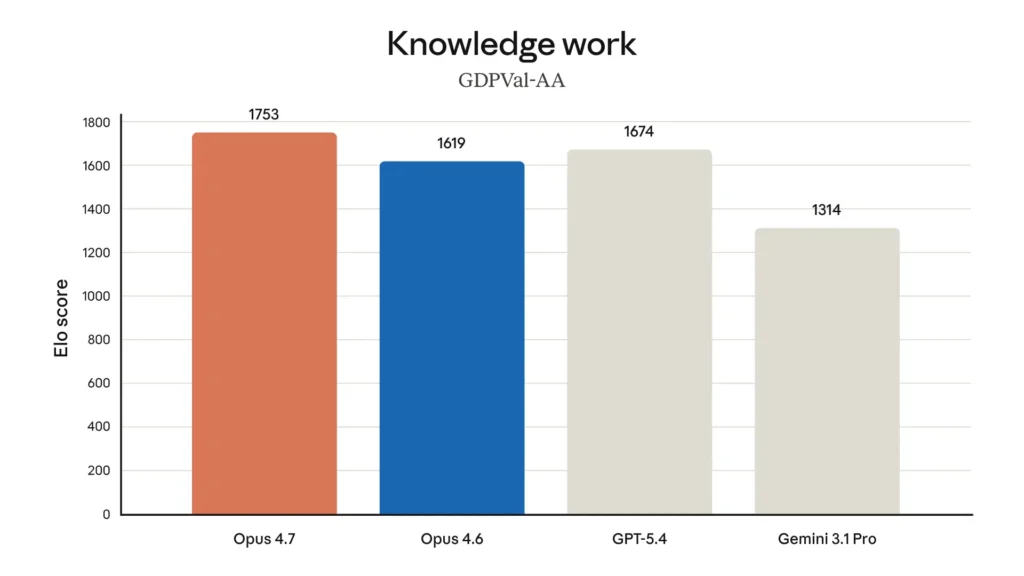
Safety and Cybersecurity Safeguards
The bar to clear is high. In May 2026, Palisade Research found Opus 4.6 self-replicated in 81% of hacking tests, more than any other frontier model evaluated, so Opus 4.7’s safeguards arrive on top of an already capable base.
Opus 4.7 maintains a similar safety profile to Opus 4.6, which Anthropic describes as “largely well-aligned and trustworthy.” It shows improvement on honesty and prompt injection resistance, though Anthropic notes it is slightly weaker on harm-reduction advice details.
The notable addition is real-time cybersecurity safeguards. Requests involving prohibited or high-risk cybersecurity topics may trigger automatic refusals. This is a direct consequence of the Claude Mythos situation, where Anthropic discovered its most powerful models could find and exploit software vulnerabilities at a level that rivals skilled human security researchers.
Cybersecurity capabilities in Opus 4.7 were deliberately reduced compared to Mythos Preview. Anthropic stated it would “launch new safeguards with an upcoming Claude Opus model” before deploying Mythos-class capabilities more broadly, and Opus 4.7 appears to be that model.
For legitimate security professionals, Anthropic has launched a Cyber Verification Program that allows applying for exceptions to the built-in safeguards.
How It Compares to Opus 4.6
| Aspect | Claude Opus 4.6 | Claude Opus 4.7 |
|---|---|---|
| Coding (93-task) | Baseline | +13% |
| Rakuten-SWE-Bench | Baseline | 3x more tasks resolved |
| Visual acuity | 54.5% | 98.5% |
| Document reasoning (OfficeQA Pro) | Baseline | 21% fewer errors |
| Max image resolution | 1,568px / 1.15MP | 2,576px / 3.75MP |
| Context window | 1M tokens | 1M tokens |
| Max output tokens | 128K | 128K |
| Effort levels | low, medium, high, max | low, medium, high, xhigh, max |
| Extended thinking | Supported | Removed (adaptive only) |
| Temperature/top_p/top_k | Supported | Removed |
| Pricing (input/output) | $5 / $25 per 1M tokens | $5 / $25 per 1M tokens |
The biggest jumps are in vision (54.5% to 98.5% on visual acuity) and production coding (3x on Rakuten-SWE-Bench). The tradeoff is tighter API constraints: no more manual thinking budgets, no sampling parameter control, and a tokenizer that uses up to 35% more tokens on the same input.
Where It Sits in the Claude Lineup
At the time of the 4.7 launch, Anthropic had three active model tiers plus the restricted Mythos tier. The current lineup and rates look like this:
| Model | Best For | Pricing (in/out per 1M) |
|---|---|---|
| Haiku 4.5 | Fast, lightweight tasks | $1 / $5 |
| Sonnet 5 | Balanced performance and cost | $2 / $10 to Aug 31, 2026, then $3 / $15 |
| Opus 5 | Complex reasoning, agentic coding | $5 / $25 |
| Opus 4.7 (legacy) | The model this article covers | $5 / $25 |
| Fable 5 | Highest available capability | $10 / $50 |
| Mythos 5 | Cybersecurity (limited availability) | $10 / $50 |
Opus 4.7 was the most capable model you could actually use when it launched; that title now belongs to Opus 5. Mythos Preview scores higher on every benchmark but remains locked behind Project Glasswing, available only to platform partners like Apple, Google, and Microsoft.
Pricing and Availability
Pricing is unchanged from Opus 4.6:
- Input: $5 per million tokens
- Output: $25 per million tokens
- Prompt caching discount: Up to 90% savings
- Batch processing discount: 50% savings
- US-only inference: 1.1x pricing multiplier
The model is available across:
- Claude Pro, Max, Team, and Enterprise subscriptions
- Claude API as
claude-opus-4-7 - Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Foundry
The 1M token context window is included at standard pricing with no long-context premium. Maximum output is 128K tokens.
What This Means for You
For developers and API users. The breaking changes are the most pressing concern. If your code sets temperature, top_p, top_k, or uses extended thinking budgets, those calls will start returning 400 errors on Opus 4.7. The migration path is straightforward: switch to adaptive thinking, remove sampling parameters, and use prompting to control output behavior. The new xhigh effort level and task budgets give you finer control over the quality/cost tradeoff.
For Claude Code users. Opus 4.7 is already the default model in Claude Code. Anthropic has also added a new /ultrareview slash command for more thorough code reviews. The model’s stricter instruction following and improved self-correction should translate to fewer rounds of back-and-forth on complex tasks. Cowork, Anthropic’s desktop AI agent, is one of the clearest places to see Opus 4.7 in action; see our full Claude Cowork guide for what it does, how to set it up, and the new Dispatch mobile feature. For how Cowork (running on Opus 4.7) stacks up against Google’s new agent, see our Gemini Spark vs Claude Cowork comparison.
For everyday AI users, Opus 4.7 won’t feel like a big leap over 4.6. The improvements are mainly useful if you work a lot with images, documents, or longer, multi-step tasks; it follows instructions more closely and handles context a bit better. If you want to try Opus 4.7 alongside ChatGPT, Gemini, Grok, and DeepSeek, you can access them all in one place with Fello AI on Mac, iPhone, and iPad for $9.99/month (also covered in our best AI apps for iPhone ranking), with 25,000+ five-star reviews.
This is Anthropic’s fourth Opus release in six months (4.1, 4.5, 4.6, 4.7), and the pace is not slowing down. With Mythos-class capabilities waiting in the wings and Opus 4.7’s new cybersecurity safeguards testing the waters, expect the next Opus to push the boundary further on what’s available to the general public.
In related coverage, read about the Apple M5 exploit built with Claude Mythos.




