
On June 4, 2026, NVIDIA released Nemotron 3 Ultra, a fully open 550 billion parameter reasoning model built specifically for long running agents. According to benchmark platform Artificial Analysis, it is now the most capable open model to come out of a US lab, scoring 48 on the Artificial Analysis Intelligence Index. That puts it well ahead of every other open American model and lands it in what Artificial Analysis calls the most attractive quadrant on its chart, combining high intelligence with fast output speed. Microsoft entered the in-house model race days earlier with its MAI lineup at Build.
Nemotron 3 Ultra is a flagship example of open source AI from a US lab, with fully published weights anyone can pull from Hugging Face.
What makes Nemotron 3 Ultra different is the design goal. NVIDIA did not build this to win single turn chatbot comparisons. According to the NVIDIA blog, it built it to orchestrate agents that plan, call tools, delegate to sub agents, read observations, and recover from errors across hundreds of turns, while burning fewer tokens than comparable open models. NVIDIA claims up to 5x higher throughput and up to 30% lower cost to complete agentic tasks than other open models in its class.
In this article we walk through what the model actually is, the architecture innovations behind it, the full benchmark picture, the new training method NVIDIA used, the surrounding agent stack, real availability and pricing, and how it stacks up against the strongest open models from China and the closed frontier.
What Nemotron 3 Ultra Actually Is
Nemotron 3 Ultra is a 550 billion parameter Mixture of Experts model with roughly 55 billion active parameters per token. That ratio is the headline. It carries the knowledge capacity of a very large model while only paying the inference cost of a much smaller one, which is what lets it run fast and cheap relative to dense models or denser MoE designs.
The model is built for frontier reasoning and orchestration. Inside any real agent workflow, most calls are routine, but a small critical subset demands deeper reasoning. NVIDIA designed Ultra to handle those hard calls, the ones that sustain architectural decisions across long coding sessions, synthesize contradictory evidence across hundreds of research sources, or verify chip designs against thousands of constraints. The everyday high volume work, tool calling, validation, simple execution, can be pushed down to smaller Nemotron 3 Super and Nano models, with Ultra acting as the orchestrator.
It is also fully open in the way that matters most. NVIDIA released the weights, the training data pipeline, and the recipes, all under the permissive OpenMDW-1.1 license from the Linux Foundation. There is a base model, the post trained instruct model, and an NVFP4 quantized variant that shrinks the memory footprint.
Reasoning is configurable. The model supports a full thinking mode, a medium effort mode, and a reasoning off mode, all toggled through the chat template. It also supports a hard reasoning budget, where you set a token ceiling on the thinking trace so the model stops deliberating and answers once it hits the cap. For agent builders watching token spend, that control is a practical feature, not a gimmick.
A Brief History of Nemotron
Nemotron is NVIDIA’s open model family, and it has been quietly building credibility for a couple of years rather than chasing chatbot headlines.
The early Nemotron releases were positioned as customizable enterprise models, distributed through NVIDIA’s NeMo framework and aimed at companies that wanted to fine tune and self host rather than call a closed API. The pitch was always the same: open weights, open data where possible, and tooling to adapt the model to a specific domain.
The Nemotron 3 generation is where the family became genuinely competitive. NVIDIA shipped it as a tiered lineup. Nano is the small, on device and edge tier. Super is the mid tier workhorse for high volume execution. Ultra, the model covered here, sits at the top as the frontier reasoning and orchestration tier. The three are designed to be used together, with the larger model teaching and coordinating the smaller ones.
The strategic logic behind the family is token economics. NVIDIA’s argument, echoed by partners building on the models, is that a single frontier model running every task is wasteful. A system of models, where a strong orchestrator hands routine work to efficient executors, completes the same workflow with far fewer tokens. Ultra is the strongest teacher and planner in that system, and because it is open with a permissive license, its outputs can legally be used to post train the smaller Super and Nano models, something the license terms of most closed frontier models prohibit.
The Architecture
Nemotron 3 Ultra is not a standard transformer. NVIDIA combined several architectural ideas to push the efficiency and accuracy tradeoff in its favor.
Hybrid Mamba transformer. The model interleaves Mamba-2 layers with attention layers. Mamba layers process long sequences far more efficiently than attention, which is what makes the 1 million token context window practical. The transformer attention layers are kept where they matter, preserving precise recall so the model can retrieve specific facts out of a very large context window. This hybrid is the core of why Ultra can run long context agent workloads without the cost exploding.
LatentMoE. Instead of routing tokens to experts in the full hidden dimension, Ultra projects tokens into a smaller latent dimension first, then routes. This makes expert routing more efficient and lets a single model handle a mix of reasoning, code generation, tool calls, and domain specific logic without the routing overhead a conventional MoE would incur.
Multi token prediction. MTP lets the model predict several future tokens in a single forward pass using shared weight prediction heads. This speeds up generation directly and gives the model native speculative decoding, so deployments can draft ahead and verify, cutting latency on long outputs and multi turn workflows.
NVFP4 precision. This is one of the more interesting practical details. The same NVFP4 checkpoint runs across NVIDIA Hopper, Blackwell, and Ampere GPUs, so developers use one checkpoint everywhere instead of maintaining separate builds per architecture. NVIDIA says NVFP4 delivers up to 5x higher throughput per GPU at the same interactivity compared to BF16 on Blackwell. The model was pre trained with a quantization aware approach so the low precision checkpoint holds accuracy.
On hardware, a single node deployment needs 8 B200 GPUs with roughly 1.5 TB of aggregate memory. Multi node setups run on 8 or more H100, H200, GB200, or GB300 GPUs. The model ships with deployment recipes for vLLM, SGLang, and TensorRT-LLM, with TensorRT-LLM currently limited to Blackwell.
Benchmark Results
NVIDIA published a head to head comparison against three of the strongest open models available: GLM 5.1 (744B, now succeeded by GLM 5.2), Kimi K2.6 (1T), and Qwen3.5 (397B). The pattern is that Nemotron 3 Ultra leads on agent productivity, instruction following, and long context, while trailing on raw coding and long horizon planning. That same Qwen3.5-397B base also powers Nex-N2-Pro, a separate open-weight model tuned specifically for agentic coding. Moonshot has since released Kimi K2.7 Code, the successor to the K2.6 model in that comparison.
| Benchmark | Nemotron 3 Ultra (550B) | GLM 5.1 (744B) | Kimi K2.6 (1T) | Qwen3.5 (397B) |
|---|---|---|---|---|
| Agent Productivity (PinchBench) | 91% | 84% | 91% | 89% |
| Long horizon Planning (EnterpriseOps-Gym) | 33% | 40% | 29% | 30% |
| Coding (Terminal-Bench 2.0) | 54% | 64% | 67% | 53% |
| Instruction Following (IFBench) | 82% | 77% | 74% | 78% |
| Knowledge Work (GDPVal-AA) | 1,448 | 1,594 | 1,508 | 1,192 |
| Professional Work (ProfBench Search) | 56% | 46% | 56% | 53% |
| Long Context (Ruler @1M) | 95% | N/A (max 256K) | N/A (max 256K) | 90% |
The standout is long context. Ultra holds 95% on Ruler at 1 million tokens, while both GLM 5.1 and Kimi K2.6 top out at 256K context and cannot run the test at all. For agent workloads that need to hold a large codebase, a long research corpus, or an extended conversation history in context, this is a real structural advantage.
The model card adds a deeper benchmark set from NVIDIA’s own evaluations:
- SWE-Bench Verified: 71.9, with consistent 65 to 70.4 scores across the Pi, OpenHands, Hermes, OpenCode, and Mini SWE Agent harnesses
- SWE-Bench Multilingual: 67.7
- Terminal Bench 2.1: 56.4
- BrowseComp: 44.4
- LiveCodeBench v6: 89.0
- IOI 2025: 570.0
- IMOAnswerBench: 88.6 without tools, 92.3 with tools
- MMLU-Pro: 86.8
- RULER at 1M: 94.7
- LongBench v2: 61.9
- MMLU-ProX across 10 languages: 83.0
The framework consistency on SWE-Bench is worth flagging. A model that scores between 65 and 70.4 regardless of which agent harness runs it is more dependable in production than one that only shines in a single tuned setup. For agent builders, predictable behavior across harnesses matters as much as a peak score.
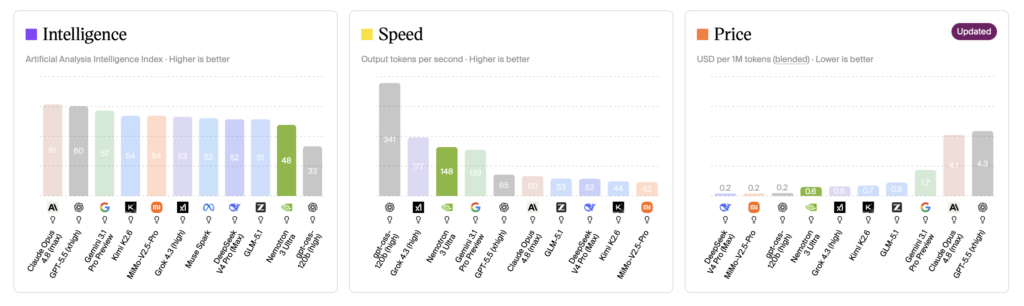
On the broader Artificial Analysis Intelligence Index, Nemotron 3 Ultra scores 48. That makes it the most capable open US model, ahead of Gemma 4 31B (39), Nemotron 3 Super (36), and gpt-oss-120b (33). It does not catch the strongest open model from China, Kimi K2.6, which sits at 54, and the closed frontier leader Opus 4.8 is further ahead at 61.
Speed and Cost Efficiency
Accuracy is only half the pitch. The other half is throughput and cost, and this is where Nemotron 3 Ultra makes its strongest case.
NVIDIA claims 5x higher throughput than other open models in its class, and the independent numbers back the direction. On provider DeepInfra, Artificial Analysis measured Nemotron 3 Ultra delivering more than 300 tokens per second, while comparably sized models from DeepSeek or Moonshot currently manage only 50 to 100. That is a large gap, and it comes from the combination of the low active parameter count, NVFP4 precision, the Mamba hybrid, and multi token prediction working together.
On cost, NVIDIA ran the model through SWE-Bench and Terminal Bench 2.0 and found it completed the benchmarks using fewer total tokens and fewer tokens per turn than comparable models, lowering the cost to task completion by up to 30%. For long running agents that call the model thousands of times to finish one workflow, a 30% reduction in tokens compounds into a meaningful bill difference.
This efficiency framing is the entire reason the model exists. As agent workflows get longer, token counts grow fast, because every plan, tool call, sub agent invocation, and reasoning step gets passed back into the model. NVIDIA’s bet is that the labs and enterprises running these workflows care more about cost per completed task than about a single benchmark number, and Ultra is tuned for that metric.
Multi Teacher On Policy Distillation
The most novel piece of the training pipeline is a method NVIDIA calls Multi Teacher On Policy Distillation, or MOPD.
In MOPD, the Ultra model learns from more than 10 specialized teacher models while generating its own attempts during training. Each teacher is trained with its own domain specific pipeline, covering areas like coding, math, search, office work, and tool calling. As the student model generates rollouts across these domains, the matching teacher scores it in its area of expertise and feeds back a dense reward signal. So a coding rollout gets graded by the coding teacher, a math rollout by the math teacher, and so on.
Two design choices make this efficient. First, the whole loop runs asynchronously, with student rollout generation, teacher scoring, and student optimization fully pipelined so no stage stalls waiting on another. Second, the process is iterative. After producing an MOPD trained checkpoint, NVIDIA initializes new rounds of teacher training from the updated student, then merges those improvements into the next MOPD stage. Student and teachers co evolve, which lets capability keep climbing across domains rather than plateauing.
The teacher lineup is itself notable, because the model card lists which models contributed. It includes Qwen3 variants, DeepSeek V3, R1, and V4-Pro, GPT-OSS-120B, GLM-5 and GLM-4.7, Mistral variants, and phi-4. In other words, NVIDIA distilled from a broad set of strong open models, which is only legally clean because Ultra is itself an open model with a permissive license and those teachers permit it.
The earlier stages are more conventional. Pre training runs on roughly 20 trillion tokens with a September 2025 cutoff using Megatron-LM. Supervised fine tuning, with a May 2026 cutoff, focuses on code, math, science, tool calling, and instruction following. Reinforcement learning uses asynchronous GRPO across math, code, science, and multi step tool use environments, built on NeMo RL and NeMo Gym. MOPD sits on top as the final refinement, and NVIDIA has released the MOPD recipe through NeMo-RL so others can reproduce it.
Training Data and Transparency
NVIDIA leans hard on data transparency as a selling point, which matters specifically for enterprise and sovereign AI buyers who need to know where training data came from.
Building on its existing pre training foundation, Nemotron 3 Ultra added 212 billion new tokens targeting three specific domain gaps:
- 4 billion tokens of synthetic legal data, which lifted the proxy LegalBench average from 64.6% to 74.7%
- 35 billion tokens of synthesized Wiki based data, which boosted proxy SimpleQA from 40.2% to 50.2%
- 173 billion refreshed GitHub tokens through September 30, 2025
On the post training side, this launch released 10 million new supervised fine tuning samples, 1 million new RL tasks across multiple domains, and 15 net new RL environments. That brings the cumulative open Nemotron totals to 50 million SFT samples, 2 million RL tasks, and 55 RL environments. The full training corpus the model card reports is about 14.8 trillion tokens across 226 datasets, a mix of public sources, crawled web and code data, and synthetic data generated by teacher models.
Releasing the RL environments and SFT data is the part that separates this from a typical open weights drop. Anyone can fine tune Ultra for their own domain using LoRA, full SFT, or reinforcement learning through the NeMo libraries, and NVIDIA ships recipes for each, including H100 and GB200 specific configurations.
The Agent Stack Around the Model
Nemotron 3 Ultra does not ship as a bare model. NVIDIA released it alongside a reference stack for running autonomous agents more safely.
Hermes Agent and OpenClaw are the agent harnesses, providing the orchestration loops, memory, and tools for multi turn workflows. Hermes Agent is now officially supported with Nemotron. NVIDIA OpenShell, in early preview as part of the NVIDIA Agent Toolkit, is the secure runtime where autonomous agents and their generated code actually execute. NVIDIA NemoClaw is the open source blueprint that ties it together, installing the OpenShell runtime with a single command so agents like Hermes can run alongside open models in a sandboxed environment.
Adoption is already showing up from partners. Enterprise AI company Glean added Nemotron 3 Ultra to its platform, citing the model delivering 91% of frontier LLM completeness at the cost profile of an open model, and positioning it as the cost effective option for everyday enterprise work across its 30 plus model lineup. Glean’s own agentic search model, Waldo, is post trained on the smaller Nemotron 3 Nano and reportedly runs with 50% lower latency and 25% fewer tokens, which is exactly the system of models pattern NVIDIA is pushing.
Aible, an enterprise agent vendor, ran a joint hackathon with NVIDIA’s NemoClaw team comparing Nemotron 3 Ultra against another leading reasoning model on an identical OpenClaw task inside OpenShell. The task required the agent to find the right sub agent, identify the correct dataset, run the analysis, post the result to Slack, and save the plan for reuse. Aible reported that Ultra planned more directly, backtracked less, was first to post to Slack, followed every part of the instruction on the first try, and successfully saved the executed plan for deterministic reuse, while the comparison model missed an instruction and failed its first Slack call. Vendor benchmarks always deserve a grain of salt, but the result is consistent with the model’s strong PinchBench and IFBench scores.
If you want to compare Nemotron 3 Ultra against the closed frontier without standing up GPU infrastructure, Fello AI gives you Claude, GPT, Gemini, DeepSeek, Perplexity, and more in a single native app for Mac, iPhone, and iPad. One subscription, every frontier model, no juggling separate accounts.
Two More Models in the Launch
NVIDIA shipped two additional Nemotron models alongside Ultra, both aimed at making agent systems safer and more capable.
Nemotron 3.5 Content Safety is an open 4 billion parameter guardrail model for classifying unsafe, disallowed, or policy violating content across text, images, and combined inputs. It covers 23 safety categories and 12 languages, and can run as an inference time guardrail, as a judge for LLM safety testing, or as a base to post train safer models using its accompanying dataset. It supports custom policies and produces reasoning trails, so enterprises can audit why a given classification was made and adapt the rules to their own domain.
Nemotron 3.5 ASR is a speech recognition model for voice native agents. It uses a cache aware streaming architecture to process audio deltas instantly, hitting sub 100 millisecond latency for real time voice. NVIDIA notes that the English predecessor already powers the voice input feature in Microsoft GitHub Copilot CLI, used by more than 20 million developers, and an independent benchmark of 50 plus on device ASR setups identified it as the strongest candidate for real time English streaming on constrained hardware. The 3.5 version extends that same architecture to 40 plus languages in a single checkpoint.
Where Nemotron 3 Ultra Falls Short
The benchmarks make the gaps clear, and NVIDIA does not hide them.
Raw coding. On Terminal-Bench 2.0, Ultra scores 54%, well behind GLM 5.1 at 64% and Kimi K2.6 at 67%. Its SWE-Bench Verified numbers are strong and consistent, but on the harder terminal coding benchmark it is the weaker model in this group. For pure code generation throughput, the larger Chinese open models currently lead.
Long horizon planning. On EnterpriseOps-Gym, Ultra scores 33%, behind GLM 5.1 at 40%. For the longest, most complex multi step planning tasks, it is not the top open model. This is a notable caveat given the model is marketed for long running agents, though it is worth noting these scores are low across the board, which says more about the difficulty of the benchmark than about any single model.
Knowledge work ceiling. On GDPVal-AA, Ultra scores 1,448 against GLM 5.1 at 1,594 and Kimi K2.6 at 1,508. On broad knowledge work it trails the larger models, which is the expected tradeoff for a model with far fewer total and active parameters.
Not the absolute frontier. At 48 on the Artificial Analysis Intelligence Index, Ultra is the best open US model, but Kimi K2.6 at 54 and the closed Opus 4.8 at 61 are clearly ahead on raw intelligence. The pitch is value and efficiency, not topping the leaderboard.
The honest read is that Nemotron 3 Ultra wins on the axes NVIDIA optimized for, agent productivity, instruction following, long context, speed, and cost, and trails on the axes it traded away, raw coding, deep planning, and peak knowledge.
How It Compares
| Capability | Nemotron 3 Ultra | Kimi K2.6 | GLM 5.1 | Opus 4.8 |
|---|---|---|---|---|
| Total parameters | 550B | 1T | 744B | closed |
| Active parameters | 55B | larger | larger | closed |
| AA Intelligence Index | 48 | 54 | not listed | 61 |
| Agent productivity (PinchBench) | 91% | 91% | 84% | not listed |
| Instruction following (IFBench) | 82% | 74% | 77% | not listed |
| Coding (Terminal-Bench 2.0) | 54% | 67% | 64% | not listed |
| Long context | 1M tokens (95% Ruler) | 256K max | 256K max | large |
| Output speed | 300+ tok/s | 50 to 100 tok/s | varies | closed |
| Open weights | yes, OpenMDW-1.1 | yes | yes | no |
The shape of the comparison is consistent. Against Kimi K2.6 and GLM 5.1, Nemotron 3 Ultra is the smaller, faster, cheaper model that matches or beats them on agent productivity, instruction following, and long context, while conceding raw coding and peak intelligence. It is roughly half the parameter count of GLM 5.1 and well under half of Kimi K2.6, yet it ties the trillion parameter Kimi on PinchBench and runs three to six times faster on throughput.
Against the closed frontier, the gap is real but the value proposition is different. Opus 4.8 at 61 on the intelligence index is the stronger reasoner, but it is a closed API you cannot self host, fine tune freely, or use to teach your own smaller models. Glean’s framing, 91% of frontier completeness at open model cost, captures the actual decision most enterprises face. For the critical 9% of tasks you route to the frontier, for the routine 91% you run an open model like Ultra and save the spend.
For Chinese language and pure coding workloads, the larger Chinese open models still have an edge. For English agent workflows where cost, speed, and tool use reliability dominate, Ultra is the more practical pick.
Availability and Pricing
Nemotron 3 Ultra is available right now through a wide set of channels, which is unusual breadth for a launch day open model.
You can try it on Perplexity with a Pro subscription or through their API, and access it through OpenRouter, Anaconda, or build.nvidia.com. The weights are downloadable from Hugging Face, in both BF16 and NVFP4 variants, and the model is packaged as an NVIDIA NIM microservice for optimized self hosting.
The cloud and inference provider list is long: AWS JumpStart, Amazon EKS, Baseten, Bitdeer AI, CoreWeave, Crusoe, DeepInfra, Dell Enterprise Hub, DigitalOcean, Eigen AI, fal, Fireworks AI, FriendliAI, GMI Cloud, Google Cloud, Lightning AI, Microsoft Foundry, Modal, Nebius Token Factory, Prime Intellect, Simplismart, Together AI, and Vultr. Agent harness integrations cover BlackBox AI, Cline, CrewAI, Factory AI, Hermes Agent, Kilo Code, LangChain Deep Agents, OpenClaw, OpenCode, OpenHands, and Pi.
NVIDIA has not published a single official per token price, since the model is open and pricing is set by each inference provider. The competitive signal is throughput. At 300 plus tokens per second on DeepInfra against 50 to 100 for similarly sized models, the effective cost per task lands well below comparable open models even before the 30% token reduction NVIDIA cites.
The licensing change is part of the story. Nemotron releases now ship under OpenMDW-1.1, the Linux Foundation’s permissive license built specifically for open AI model distributions. It covers the full set of model materials, architecture, parameters, documentation, software, and related artifacts, under one framework, which removes a lot of the licensing ambiguity that slows enterprise evaluation of open models.
Why This Release Matters
Three things stand out about this launch.
First, the open US frontier just took a real step up. For most of the past year, the strongest open models came out of Chinese labs, with US open releases trailing. Nemotron 3 Ultra at 48 on the intelligence index is now clearly the best open American model, ahead of gpt-oss-120b and Gemma 4. It still does not catch Kimi K2.6, so China keeps the open crown, but the gap narrowed and NVIDIA is now a serious open model player, not just a chip vendor shipping reference models.
Second, this is a bet on the system of models thesis over the single frontier model thesis. NVIDIA, Glean, and Aible are all making the same argument: running one giant model for every task is wasteful, and the future is a strong open orchestrator handing routine work to cheap efficient executors. Ultra is explicitly designed as the teacher and planner at the top of that stack, with a permissive license precisely so its outputs can train the smaller models below it. If that pattern wins, the value shifts from owning the single best model to owning the most efficient model system.
Third, efficiency is now a first class competitive axis. Nemotron 3 Ultra leads its peer group not by being the smartest model in the room, but by completing the same agent tasks 5x faster and 30% cheaper. As agent workflows get longer and token bills grow, cost per completed task becomes the number enterprises actually optimize, and a model tuned for that metric can win deployments even when it loses benchmark headlines.
For anyone who wants to put Nemotron 3 Ultra side by side with Claude, GPT, Gemini, DeepSeek, and Perplexity without managing GPUs or separate subscriptions, Fello AI brings every frontier model into one native app for Mac, iPhone, and iPad. Test the same prompt across models, see which one handles your work best, and switch instantly. Nemotron 3 Ultra is the clearest sign yet that open models are closing on the closed frontier, and the fastest way to feel that progress is to compare them yourself.




